
DataPulse
Une suite de gestion de donnees pour l'entreprise, catalogue, lineage au niveau des colonnes, monitoring de pipelines, FinOps, gestion des secrets et gouvernance avec plus de 14 integrations de scanners a travers Snowflake, dbt, Azure Data Factory, Power BI et d'autres.
Résultats clés
Scanners de plateformes
14+ integrations
Snowflake, dbt, ADF, Power BI, Databricks, BigQuery, Airflow, Fivetran, Kafka, Looker, Tableau, PostgreSQL, MySQL, Synapse.
Envergure du backend
248 Python files
Plus de 56 classes de services, 36 modules de routes API, plus de 40 modeles de base de donnees, pile entierement asynchrone.
Authentification entreprise
SAML + SCIM + SSO
Azure AD, Okta, Google OAuth, SAML 2.0 avec provisionnement SCIM 2.0 et securite au niveau des lignes.
Infrastructure
6 Docker services
PostgreSQL, Redis, OpenSearch, FastAPI, workers ARQ, Next.js — avec des charts Helm Kubernetes pour la production.
Le problème
Ce que ce projet devait résoudre
Les equipes data en entreprise sont aveugles face a leur propre ecosysteme de donnees. Les metadonnees sont dispersees entre Snowflake, dbt, ADF, Power BI et une douzaine d'autres outils. Personne ne sait quels pipelines alimentent quels tableaux de bord, combien coute Snowflake par equipe, quand les secrets expirent ou si la qualite des donnees se degrade. Les outils existants comme Purview sont couteux, rigides et opaques.
DataPulse est ne d'un probleme concret : les equipes data en entreprise dependent d'outils couteux et opaques comme Microsoft Purview pour comprendre quelles donnees elles possedent, ou elles circulent et combien elles coutent. L'objectif etait de construire une alternative de qualite production qui donne aux equipes data une visibilite complete sur leur ecosysteme de donnees.
La plateforme est une application full-stack avec un backend asynchrone FastAPI orchestrant plus de 14 plugins de scanners qui explorent les metadonnees depuis Snowflake, dbt, Azure Data Factory, Power BI, Databricks, BigQuery, Airflow et d'autres. Chaque scanner suit un pattern d'enregistrement par decorateurs, rendant le framework extensible. Un graphe de connaissances de type Neo4j dans PostgreSQL avec OpenSearch alimente la decouverte en texte integral sur l'ensemble du catalogue.
Le frontend est une application Next.js 14 avec des graphes de lineage animes par D3.js, des tableaux de bord analytiques Recharts et des fonctionnalites entreprise comme le SAML SSO, le provisionnement SCIM et la securite au niveau des lignes. Le resultat est une plateforme qui remplace un deploiement Purview a plus de 500 000 $ par quelque chose que les equipes data peuvent reellement etendre et maitriser.
Ce qui a changé
Au lieu de payer plus de 500 000 $ pour Purview sans obtenir le lineage au niveau des colonnes ni l'attribution FinOps, les equipes disposent d'une plateforme deployable en Docker Compose, extensible avec des scanners personnalises et exploitable avec une securite de niveau entreprise.
Pourquoi c'était difficile
Le defi principal etait de construire un modele de metadonnees unifie qui normalise des APIs radicalement differentes — l'INFORMATION_SCHEMA de Snowflake, le manifest.json de dbt, les executions d'activites ADF, l'API REST de Power BI — en un catalogue unique et interrogeable avec un lineage multi-plateforme. Chaque scanner parle un langage different, et le systeme devait les correler en des flux de donnees coherents.
Contraintes
- Plus de 14 scanners de plateformes necessitaient une architecture de plugins commune — chacun avec des APIs et des modeles de metadonnees radicalement differents.
- Le lineage au niveau des colonnes devait fonctionner a travers SQL, le manifest.json de dbt et les definitions d'activites ADF — chacun exprimant les transformations differemment.
- L'isolation multi-tenant exigeait le Row-Level Security de PostgreSQL sans aucun compromis de performance sur les requetes du catalogue.
- Le SSO entreprise (SAML 2.0, SCIM 2.0, Azure AD, Okta) devait cohabiter avec une authentification JWT simple pour les equipes plus petites.
- La normalisation des couts FinOps entre les warehouses Snowflake et les ressources Azure necessitait des regles d'attribution configurables.
Mon rôle
- Conception et construction de la plateforme full-stack : backend FastAPI (248 fichiers Python), frontend Next.js (131 fichiers TSX), infrastructure Docker.
- Architecture du framework de scanners base sur des plugins avec enregistrement par decorateurs pour plus de 14 integrations de plateformes.
- Construction du suivi de lineage au niveau des colonnes avec 9 types de transformations et un score de confiance.
- Implementation de la pile d'authentification entreprise : SAML 2.0, SCIM 2.0, Azure AD, Okta, JWT, cles API.
- Conception du module FinOps avec attribution des couts, detection d'anomalies et alertes budgetaires.
- Construction du systeme de gestion des secrets avec scoring de risque et cartographie des dependances.
Preuves
À quoi ressemble réellement le produit
Captures d'écran réelles du produit, chacune illustre un argument concret de clarté, de contrôle ou d'observabilité.
 DecouverteCliquer pour agrandir
DecouverteCliquer pour agrandirExplorateur du catalogue de donnees
Vue unifiee du catalogue avec hierarchie des actifs, enrichissement des metadonnees, etiquetage et recherche en texte integral via OpenSearch sur toutes les plateformes connectees.
Les actifs de plus de 14 plateformes sont normalises en une hierarchie navigable unique — base de donnees, schema, table, colonne.
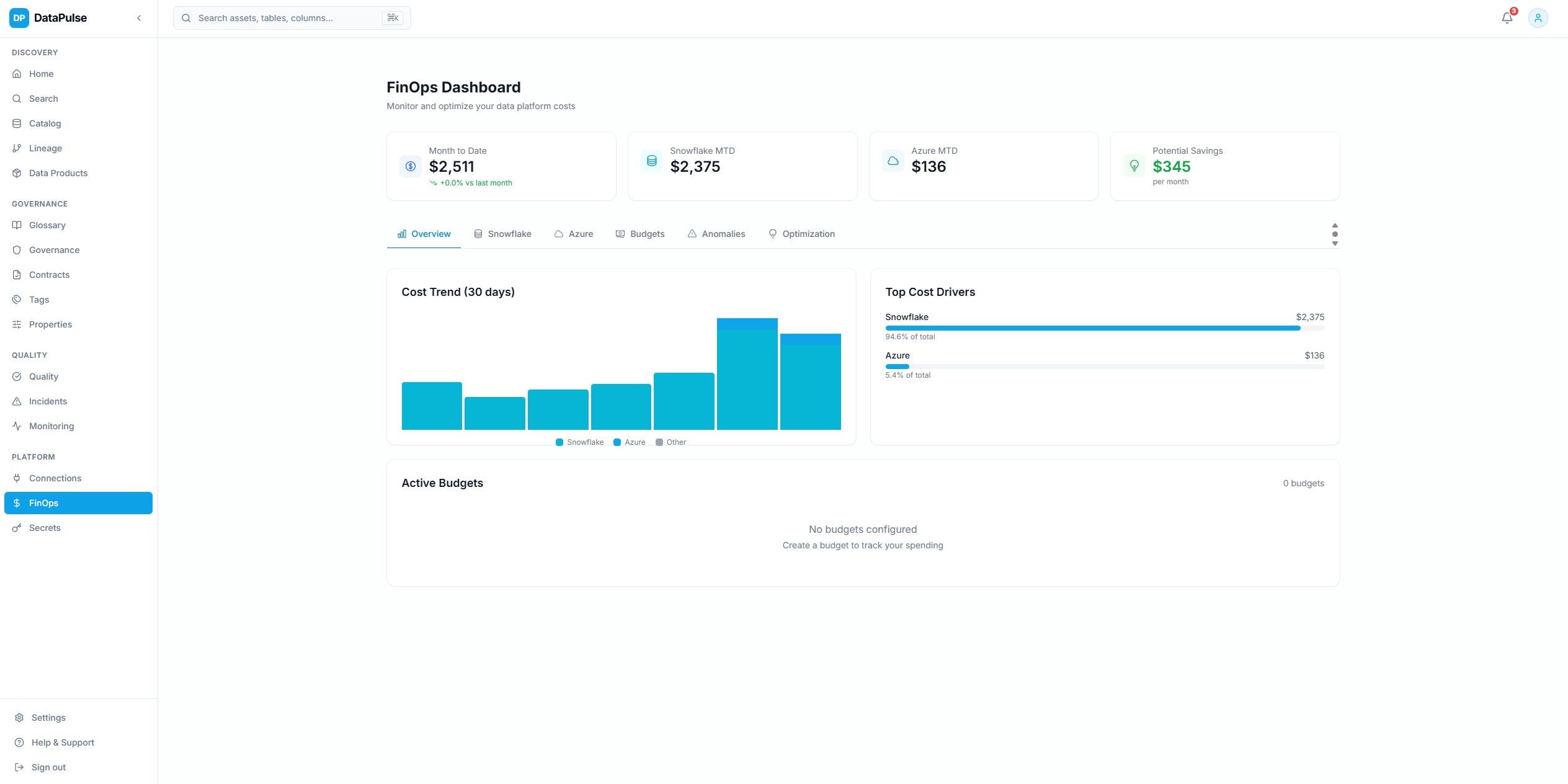 Intelligence des coutsCliquer pour agrandir
Intelligence des coutsCliquer pour agrandirTableau de bord FinOps
Visibilite unifiee des couts sur les warehouses Snowflake et les ressources Azure avec analyse de tendances, suivi budgetaire et attribution par equipe.
Les regles de normalisation et d'attribution des couts permettent aux equipes de comprendre exactement ou vont les depenses et pourquoi.
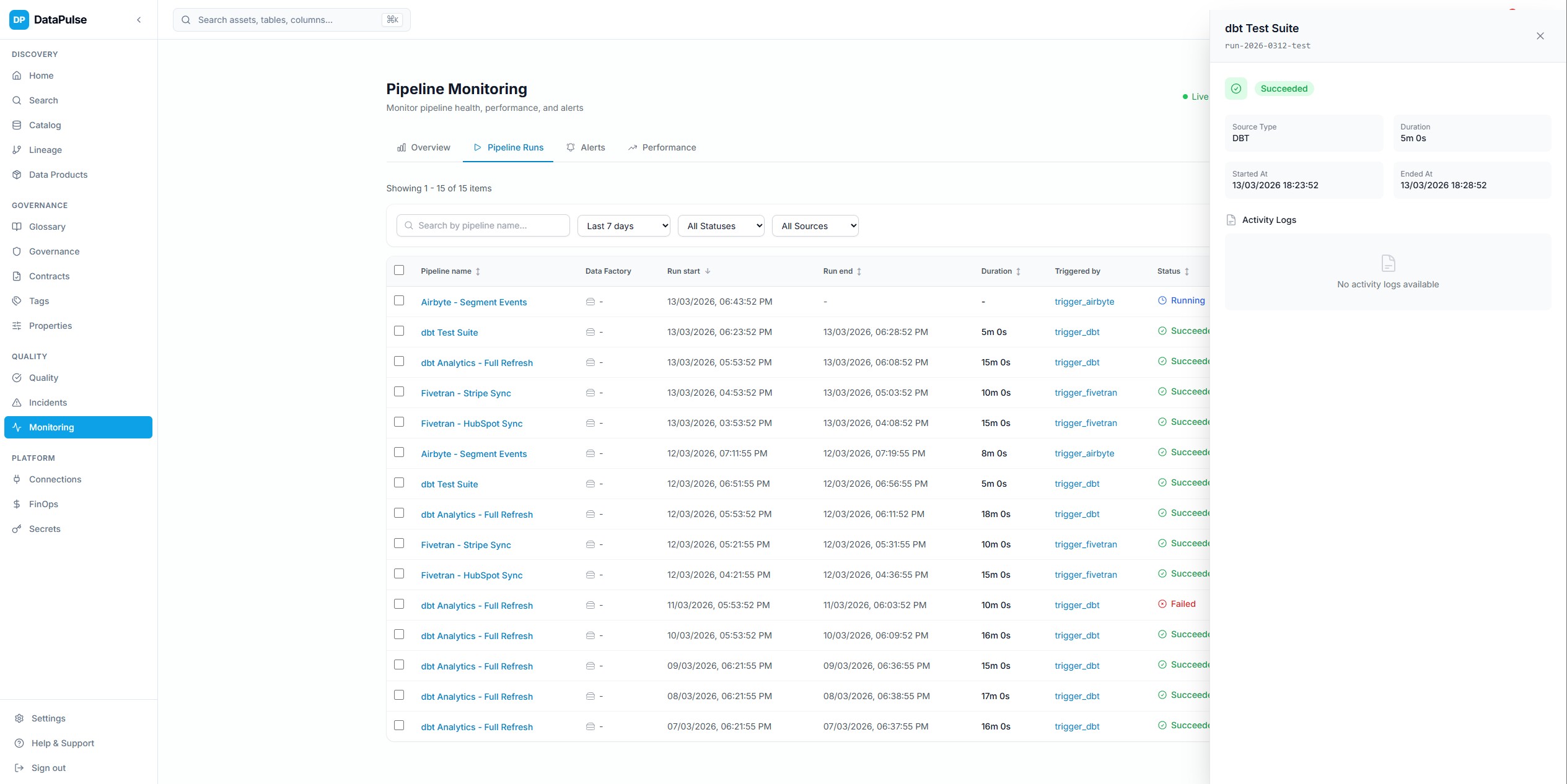 Sante operationnelleCliquer pour agrandir
Sante operationnelleCliquer pour agrandirMonitoring des pipelines
Suivi en temps reel des executions de pipelines avec agregation des statuts, surveillance des SLA, regles d'alerte et analyse des tendances historiques.
Les collecteurs d'executions pour ADF, dbt Cloud et les taches Snowflake alimentent une surface de monitoring unifiee avec des alertes configurables.
 ConformiteCliquer pour agrandir
ConformiteCliquer pour agrandirGouvernance et politiques
Gouvernance des donnees avec politiques de classification, regles de retention, securite au niveau des colonnes et workflows de certification.
Concu pour la conformite entreprise — classification des donnees, politiques d'acces et pistes d'audit en un seul endroit.
 SecuriteCliquer pour agrandir
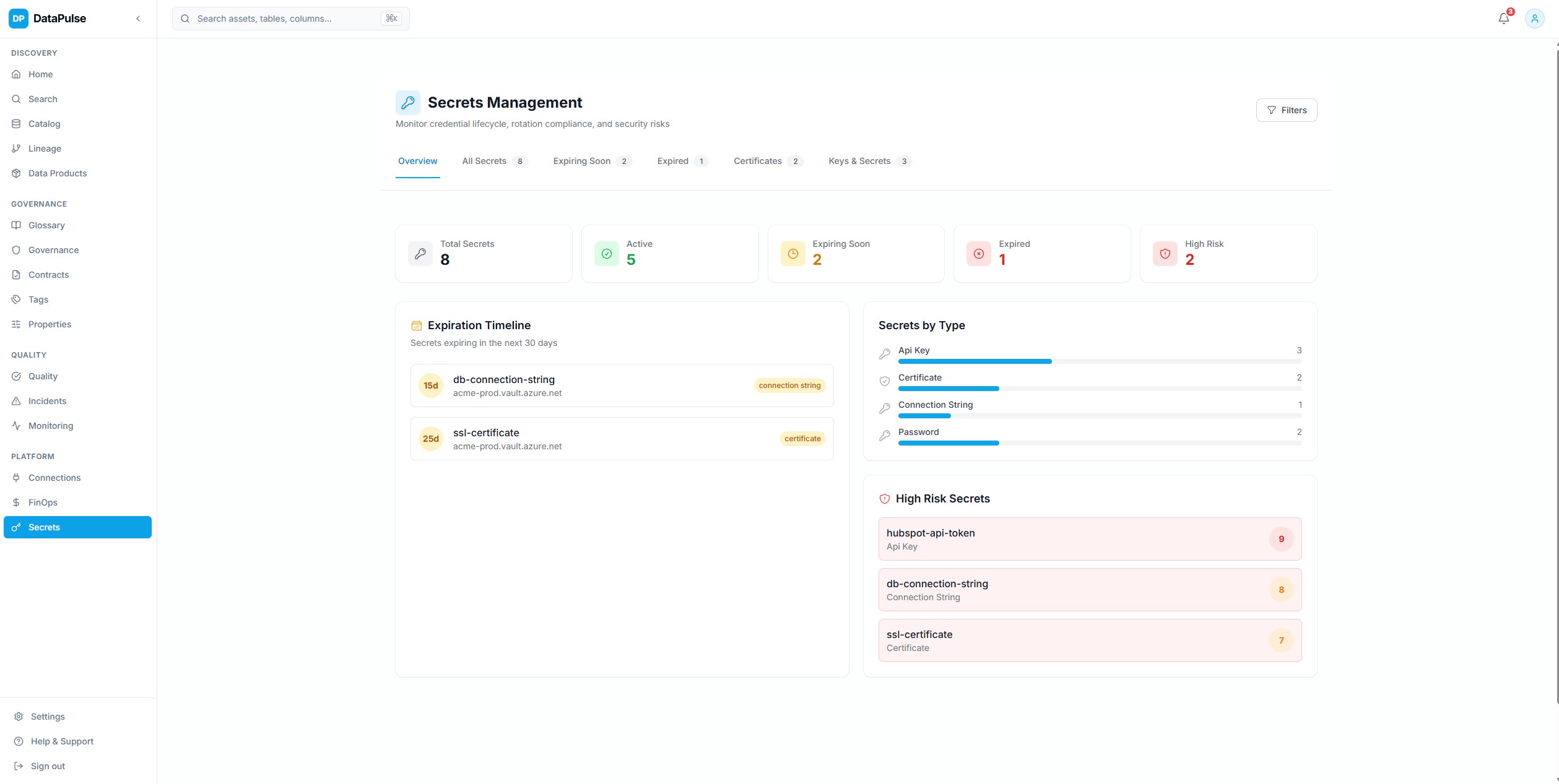
SecuriteCliquer pour agrandirGestion des secrets
Suivi du cycle de vie des secrets avec scoring de risque, alertes d'expiration, historique de rotation et cartographie des dependances vers les pipelines en aval.
13 types de secrets suivis avec un scoring de risque base sur le ML — le systeme sait quels secrets sont sur le point d'expirer et ce qui casse si cela arrive.
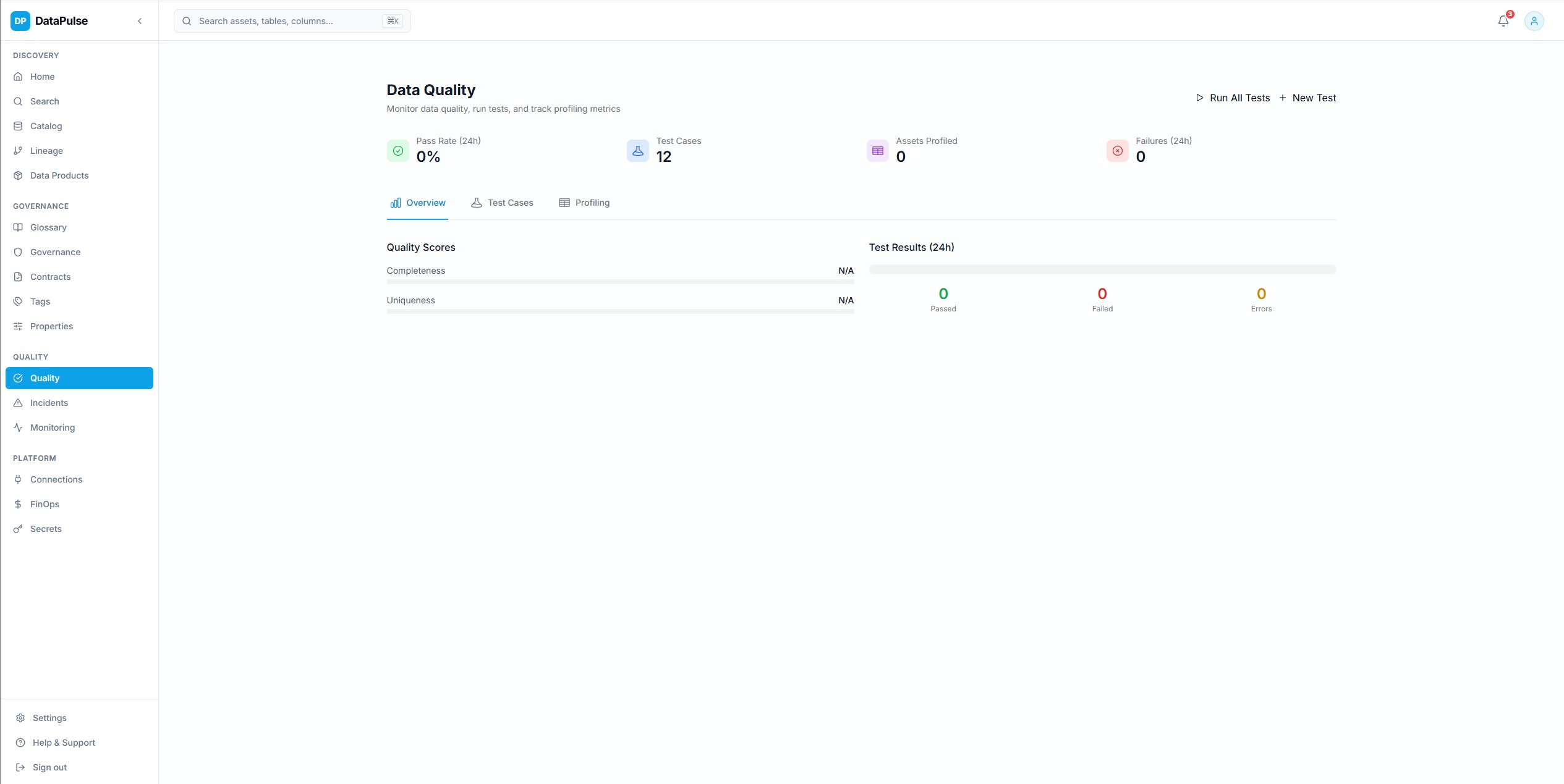 QualiteCliquer pour agrandir
QualiteCliquer pour agrandirProfilage de la qualite des donnees
Profilage statistique avec integration Soda Core, score de qualite par actif, detection de PII et identification d'anomalies via scikit-learn.
Les scores de qualite remontent des assertions au niveau des colonnes vers des KPI au niveau des tables, donnant aux equipes un signal de sante clair.
Décisions
Les compromis qui ont façonné le produit
Le travail le plus solide se révèle dans les choix faits sous pression, pas seulement dans l'interface finale.
Architecture de scanners basee sur des plugins
Défi
Plus de 14 plateformes exposent chacune leurs metadonnees via des APIs completement differentes — REST, SQL, fichiers manifestes, SDKs. Coder en dur chacune d'entre elles aurait cree un monolithe inmaintenable.
Décision
Construction d'un framework de plugins base sur des decorateurs ou chaque scanner enregistre ses capacites (@metadata_scanner, @cost_collector, @run_collector). Des classes de base abstraites definissent le contrat, et de nouvelles plateformes peuvent etre ajoutees sans toucher au code principal.
Compromis
La couche d'abstraction a ajoute de la complexite initiale mais a fait la difference entre un scanner supplementaire comme tache de 2 jours plutot qu'un refactoring de 2 semaines.
PostgreSQL RLS plutot qu'un cloisonnement applicatif
Défi
Le SaaS multi-tenant exigeait une isolation des donnees sans faille. Les clauses WHERE au niveau applicatif sont sujettes aux erreurs — un filtre oublie et les donnees fuient entre les tenants.
Décision
Implementation de politiques Row-Level Security PostgreSQL qui imposent l'isolation des tenants au niveau de la base de donnees. Meme si le code applicatif comporte un bug, la base de donnees ne renverra pas les donnees d'un autre tenant.
Compromis
Le RLS a ajoute de la complexite aux migrations et a necessite une gestion rigoureuse du contexte tenant au niveau de la session, mais la garantie de securite le justifie pour les clients entreprise.
OpenSearch en complement de PostgreSQL
Défi
La recherche dans le catalogue doit etre rapide, floue et a facettes. La recherche full-text de PostgreSQL fonctionne mais ne monte pas en charge pour des requetes a facettes complexes sur des millions d'actifs.
Décision
Ajout d'OpenSearch comme couche de recherche dediee synchronisee depuis PostgreSQL. Les mutations du catalogue ecrivent dans les deux stores, et les requetes de recherche interrogent OpenSearch avec filtrage a facettes tandis que les vues de detail interrogent PostgreSQL.
Compromis
La double ecriture ajoute une charge operationnelle (un service avec etat supplementaire) mais les performances de recherche sont passees de secondes a millisecondes avec un classement de pertinence adequat.
Architecture
Comment les données circulent dans le système
Connexion et enregistrement des scanners
L'equipe data enregistre les connexions aux plateformes (identifiants Snowflake, tokens dbt Cloud, principaux de service ADF). Chaque connexion active les plugins de scanners correspondants via le framework base sur les decorateurs.
→ Connexions authentifiees vers plus de 14 plateformes pretes pour l'extraction de metadonnees.
Scan et ingestion des metadonnees
Les workers en arriere-plan ARQ executent les scanners selon un calendrier. Chaque scanner explore les metadonnees de sa plateforme (tables, colonnes, pipelines, tableaux de bord) et normalise la sortie dans le modele d'actifs unifie avec des conventions de nommage qualifie.
→ Catalogue de metadonnees normalise avec une hierarchie d'actifs coherente sur toutes les plateformes.
Extraction et correlation du lineage
Les scanners de lineage analysent les requetes SQL (Snowflake ACCESS_HISTORY), le manifest.json de dbt et les definitions d'activites ADF pour extraire les flux de donnees au niveau des colonnes. Les relations sont correlees entre plateformes avec un score de confiance.
→ Graphe de lineage multi-plateforme au niveau des colonnes avec 9 types de transformations et analyse d'impact.
Profilage de qualite et classification
Soda Core profile les statistiques par table et par colonne. scikit-learn classifie les donnees sensibles (detection PII). Les scores de qualite remontent des assertions vers des KPI au niveau des actifs.
→ Scores de qualite par actif, signalements PII et detection d'anomalies alimentant les workflows de gouvernance.
Collecte et attribution des couts
Les collecteurs de couts recuperent l'utilisation des warehouses Snowflake et les couts des ressources Azure. Les regles de normalisation convertissent en USD. Les regles d'attribution associent les couts aux equipes, projets et pipelines via des tags.
→ Vue FinOps unifiee avec alertes budgetaires, detection d'anomalies et attribution des couts par equipe.
Recherche, gouvernance et mise a disposition
OpenSearch indexe l'ensemble du catalogue pour une recherche floue en moins d'une seconde. Les politiques de gouvernance imposent la classification, la retention et les controles d'acces. Le SAML SSO et le provisionnement SCIM gerent l'identite entreprise.
→ Plateforme de donnees prete pour la production avec authentification entreprise, gouvernance et decouverte instantanee.
DataPulse est une stack Docker Compose a 6 services avec un backend asynchrone FastAPI (248 fichiers Python, plus de 56 services) orchestrant plus de 14 scanners de plateformes via un framework de plugins base sur des decorateurs. Les workers ARQ gerent le scan en arriere-plan, avec des resultats normalises dans PostgreSQL (avec RLS pour le multi-tenant) et synchronises vers OpenSearch pour une recherche dans le catalogue en moins d'une seconde. Le frontend est une application Next.js 14 avec des graphes de lineage D3.js, des tableaux de bord Recharts et TanStack Table pour les vues riches en donnees. L'authentification entreprise prend en charge SAML 2.0, SCIM 2.0, Azure AD, Okta et Google OAuth en plus de JWT. Les charts Helm Kubernetes et les modules Terraform gerent le deploiement en production avec autoscaling horizontal des pods.
Surfaces produit
Les interfaces qui portent l'expérience
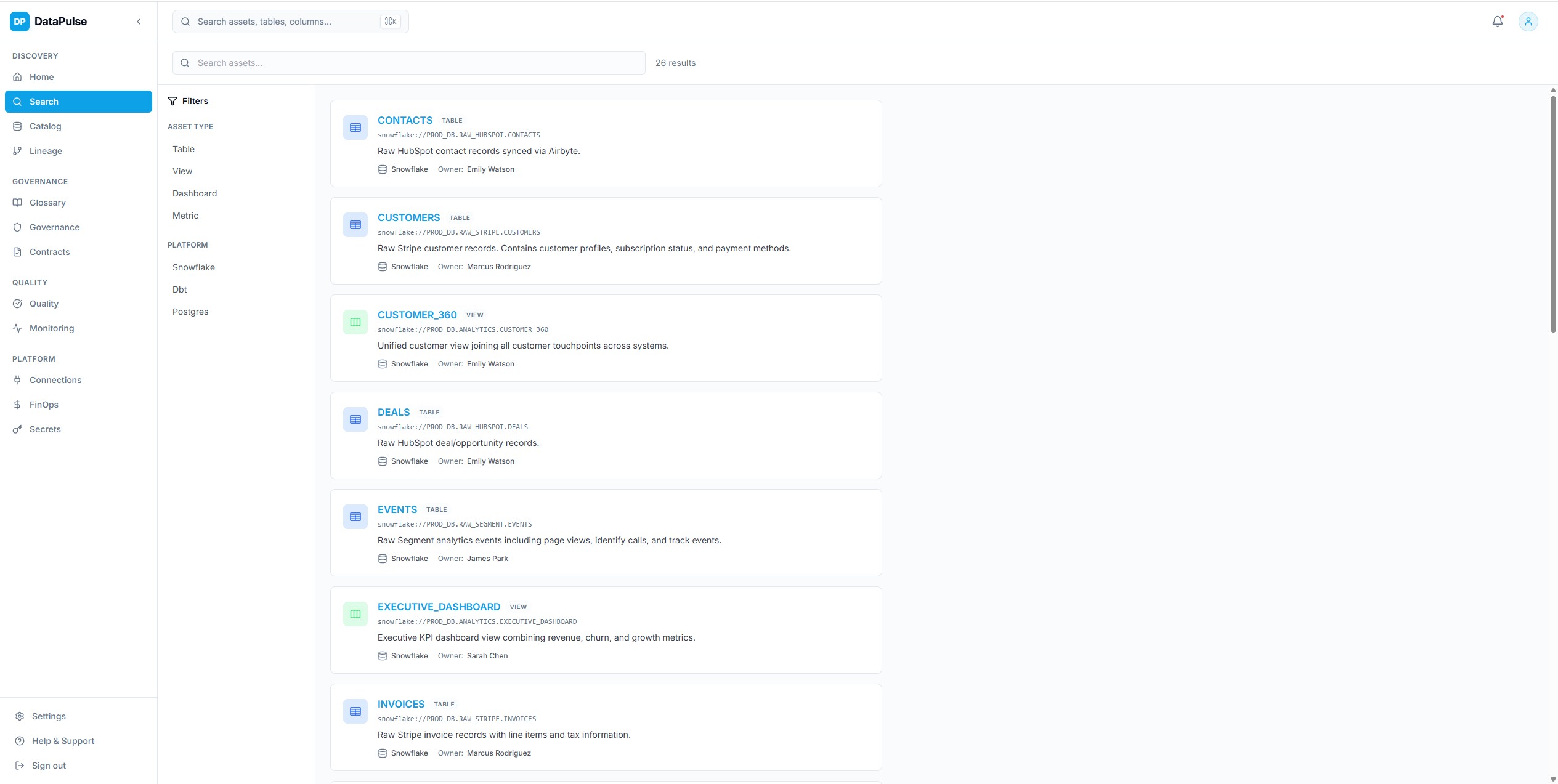
Recherche et decouverte universelles
Recherche en texte integral sur l'ensemble du catalogue de donnees via OpenSearch — correspondance floue, filtrage a facettes par plateforme, type, proprietaire, tags et classification. Concue pour repondre a la question 'ou se trouve cette donnee ?' en quelques secondes.
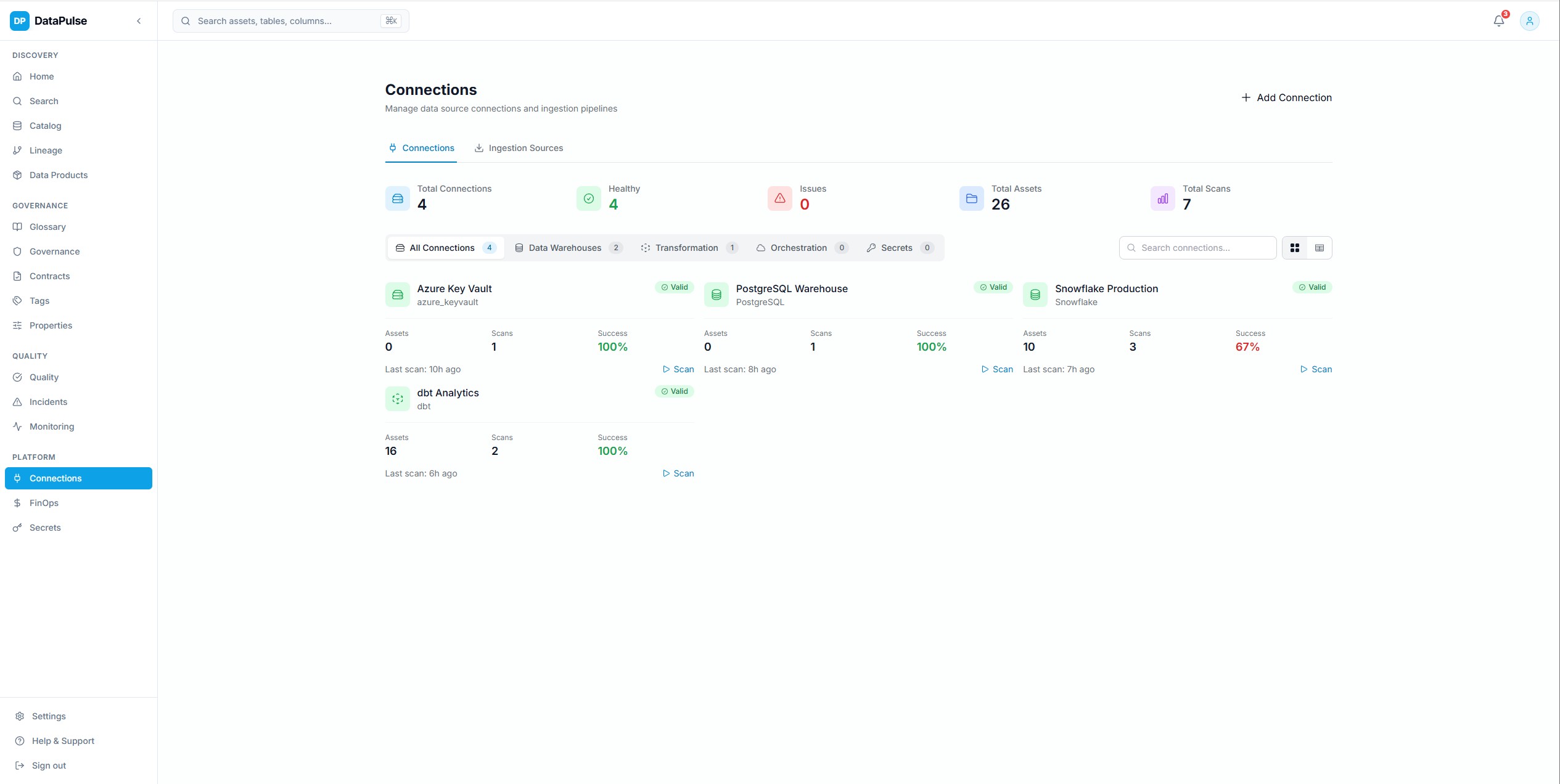
Gestion des connexions
Enregistrement et gestion des connexions vers toutes les plateformes supportees avec stockage chiffre des identifiants, surveillance de la sante et activation automatique des scanners. Prise en charge d'Azure Key Vault, des principaux de service et des tokens API.
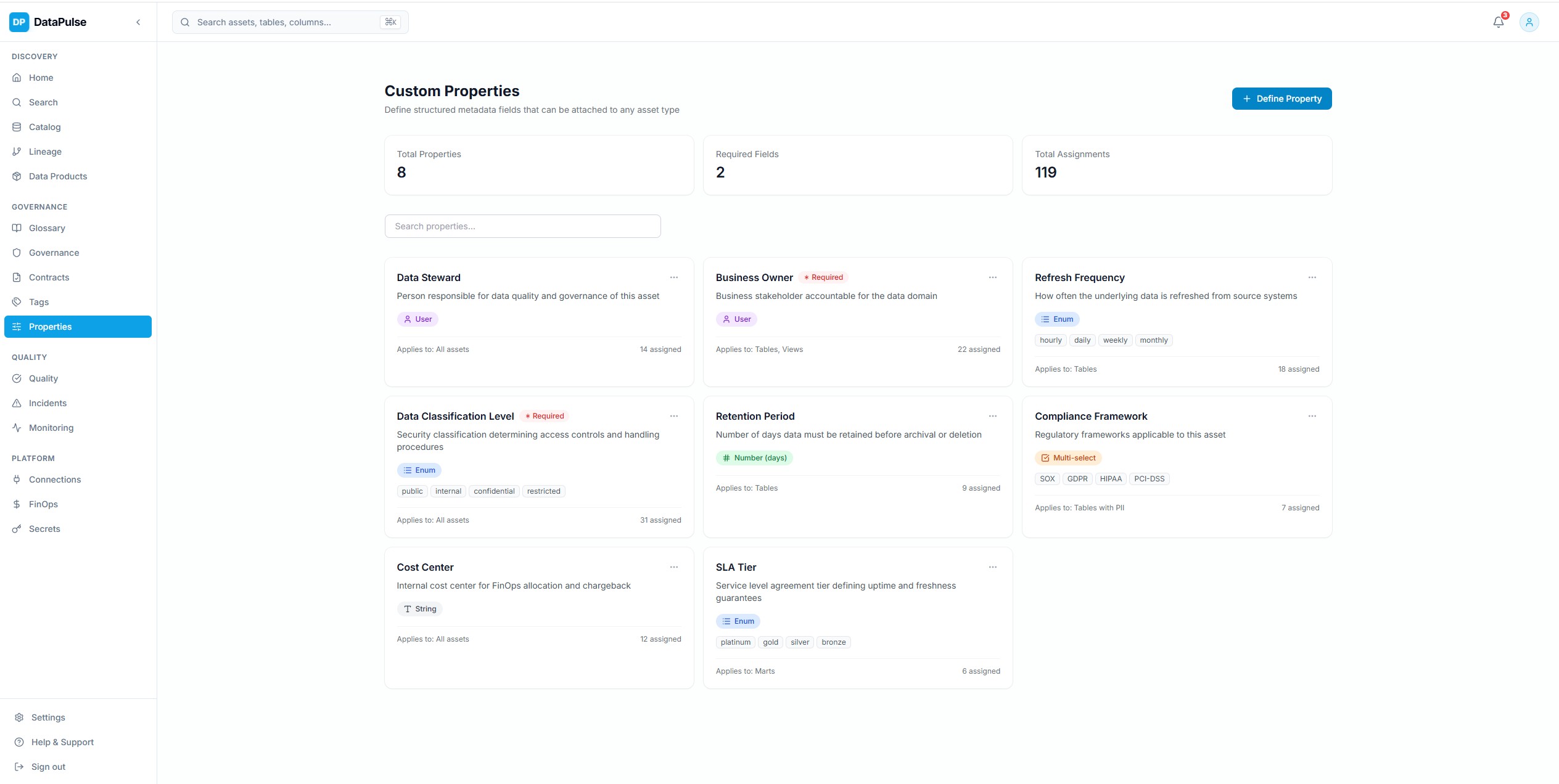
Proprietes et metadonnees des actifs
Vue enrichie des metadonnees par actif avec details du schema, types de colonnes, tags, descriptions, propriete, contexte de lineage et historique des modifications. Les proprietes personnalisees permettent un enrichissement des metadonnees specifique au domaine.
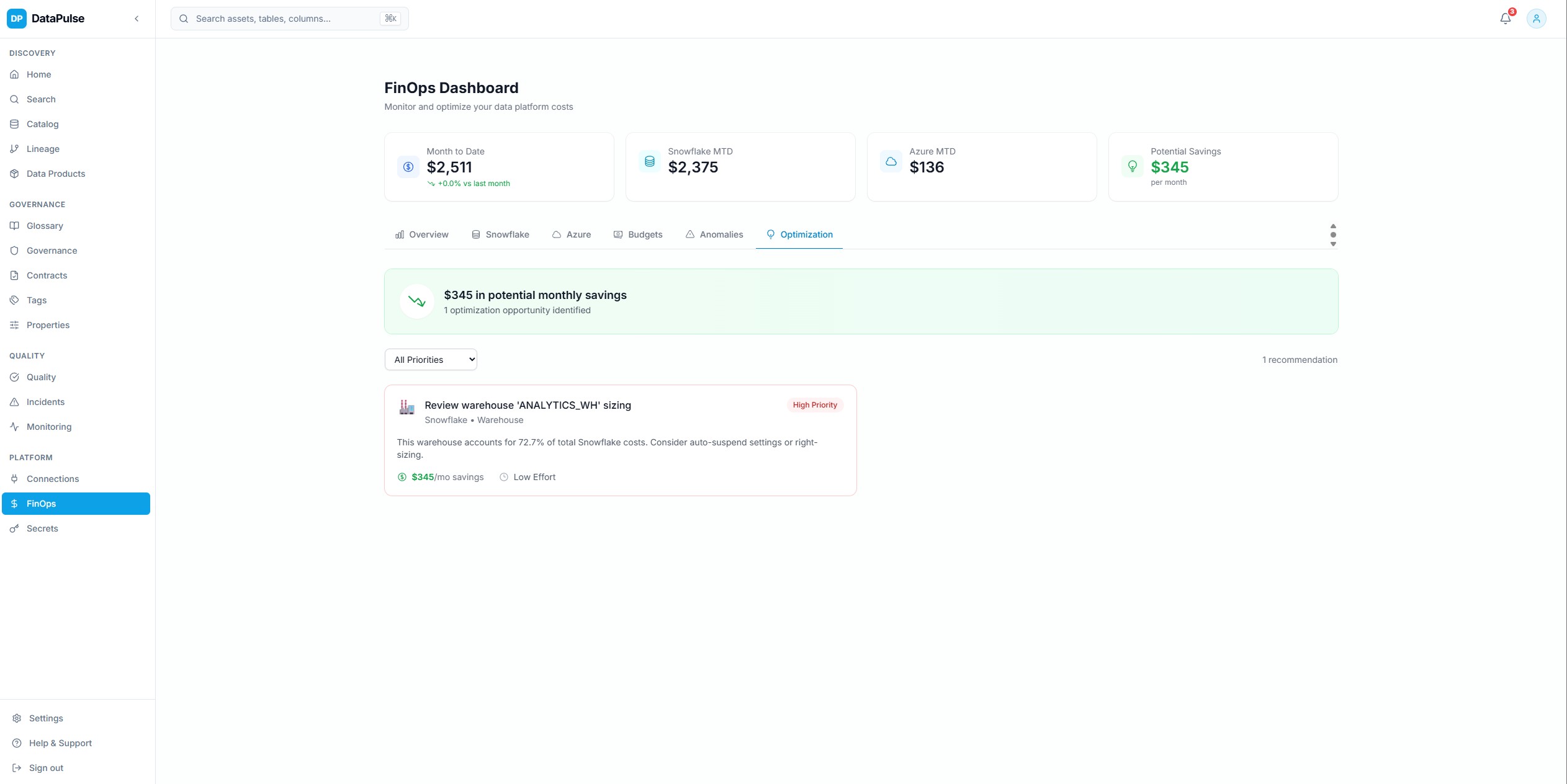
Optimisation des couts FinOps
Recommandations d'optimisation des couts basees sur les patterns d'utilisation — identification des warehouses Snowflake sous-utilises, des ressources surprovisionnees et des anomalies de couts avec des conseils de remediation actionnables.
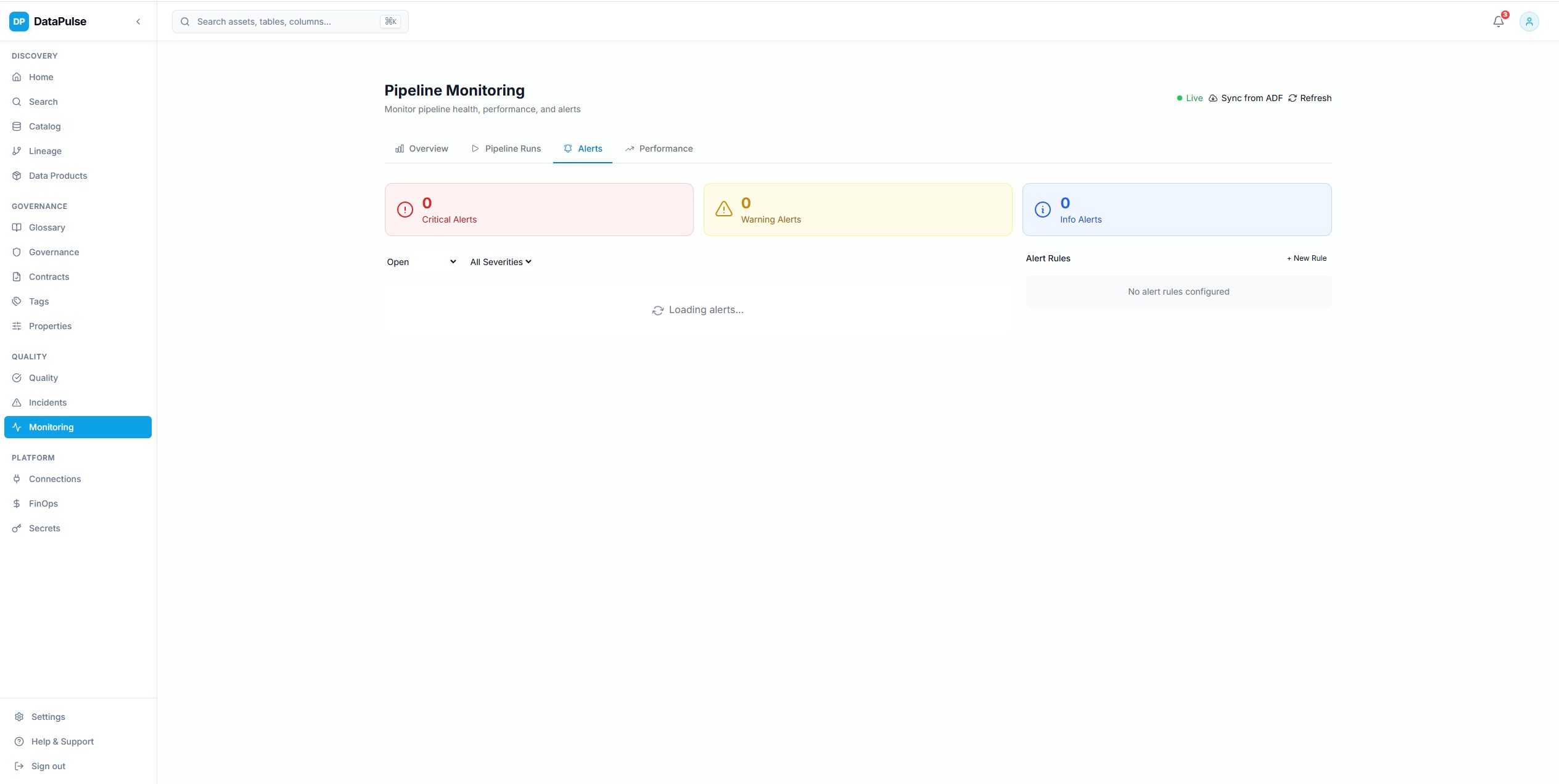
Configuration des alertes de pipelines
Regles d'alerte configurables sur les echecs de pipelines, les timeouts, les violations de SLA et les anomalies. Notifications routees vers Slack et Microsoft Teams avec le contexte complet de l'incident et des suggestions de remediation.
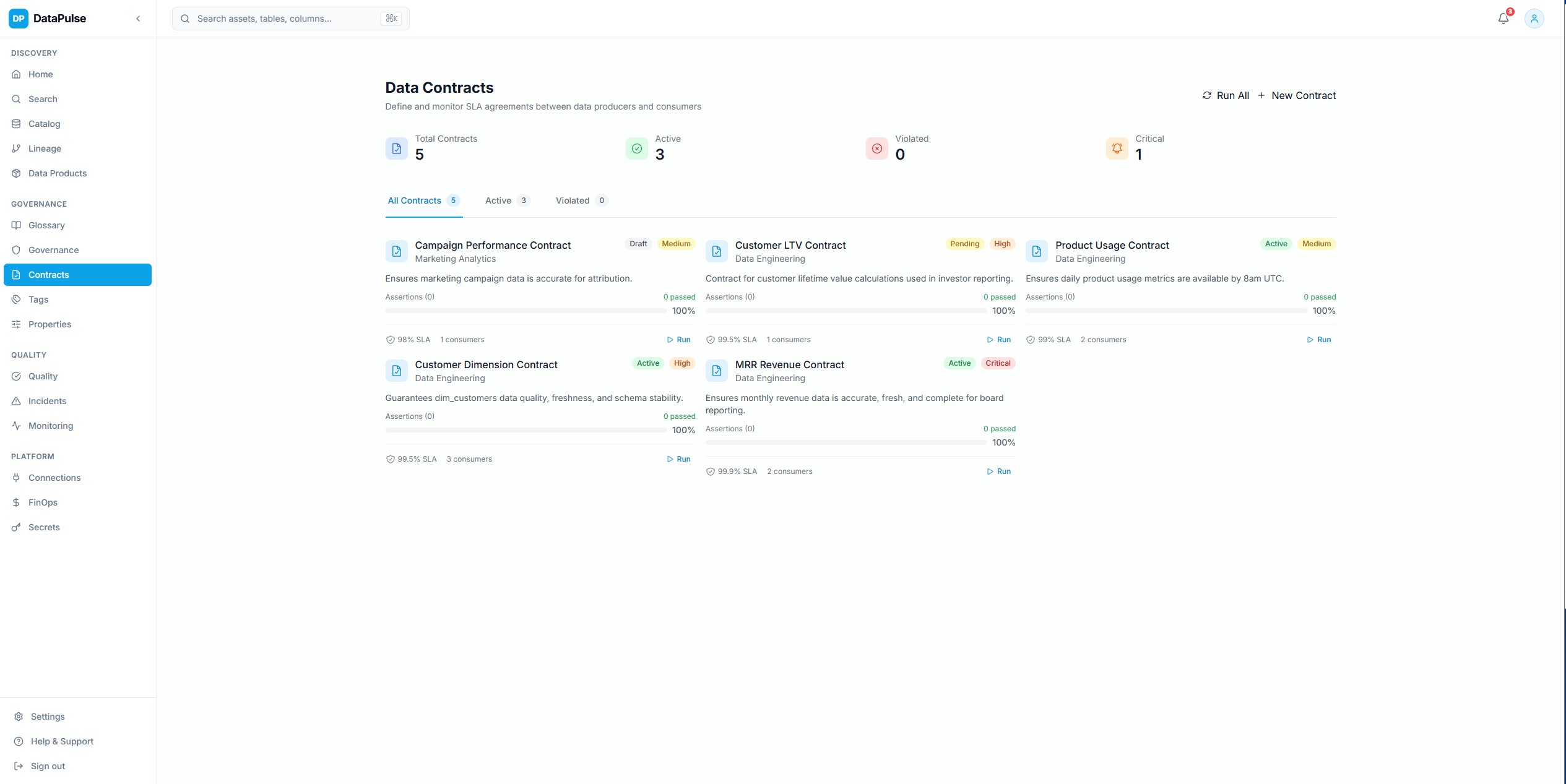
Contrats de donnees
Definition et application de contrats de donnees avec des SLA sur la fraicheur, la completude, la stabilite du schema et les seuils de qualite. Les contrats etablissent un pont entre les producteurs et les consommateurs de donnees avec des attentes claires.
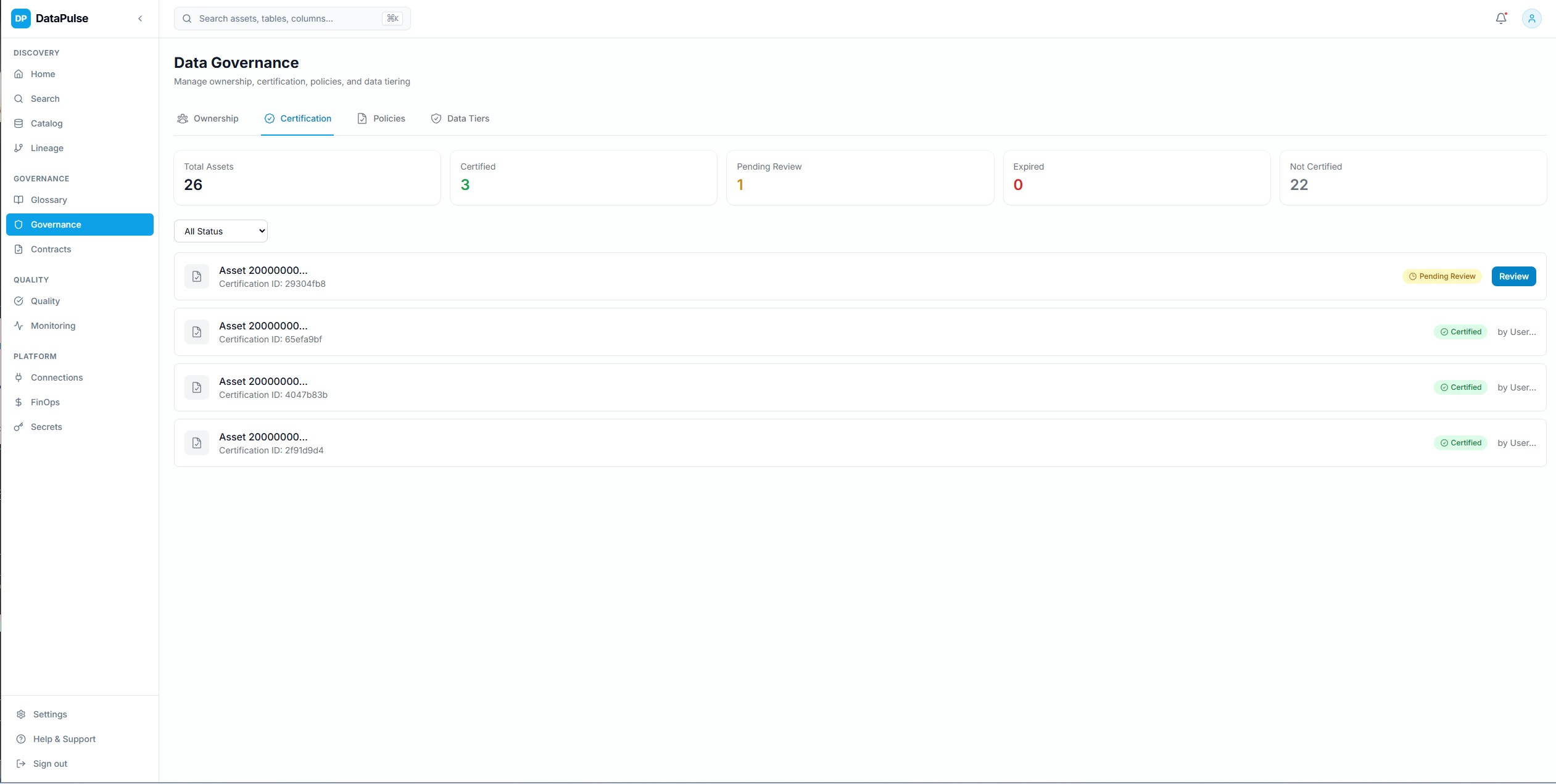
Certification de gouvernance
Workflows de certification des actifs de donnees — demande, revue, approbation et suivi des certifications avec pistes d'audit. Les actifs certifies apparaissent en evidence dans la recherche et les vues du catalogue.
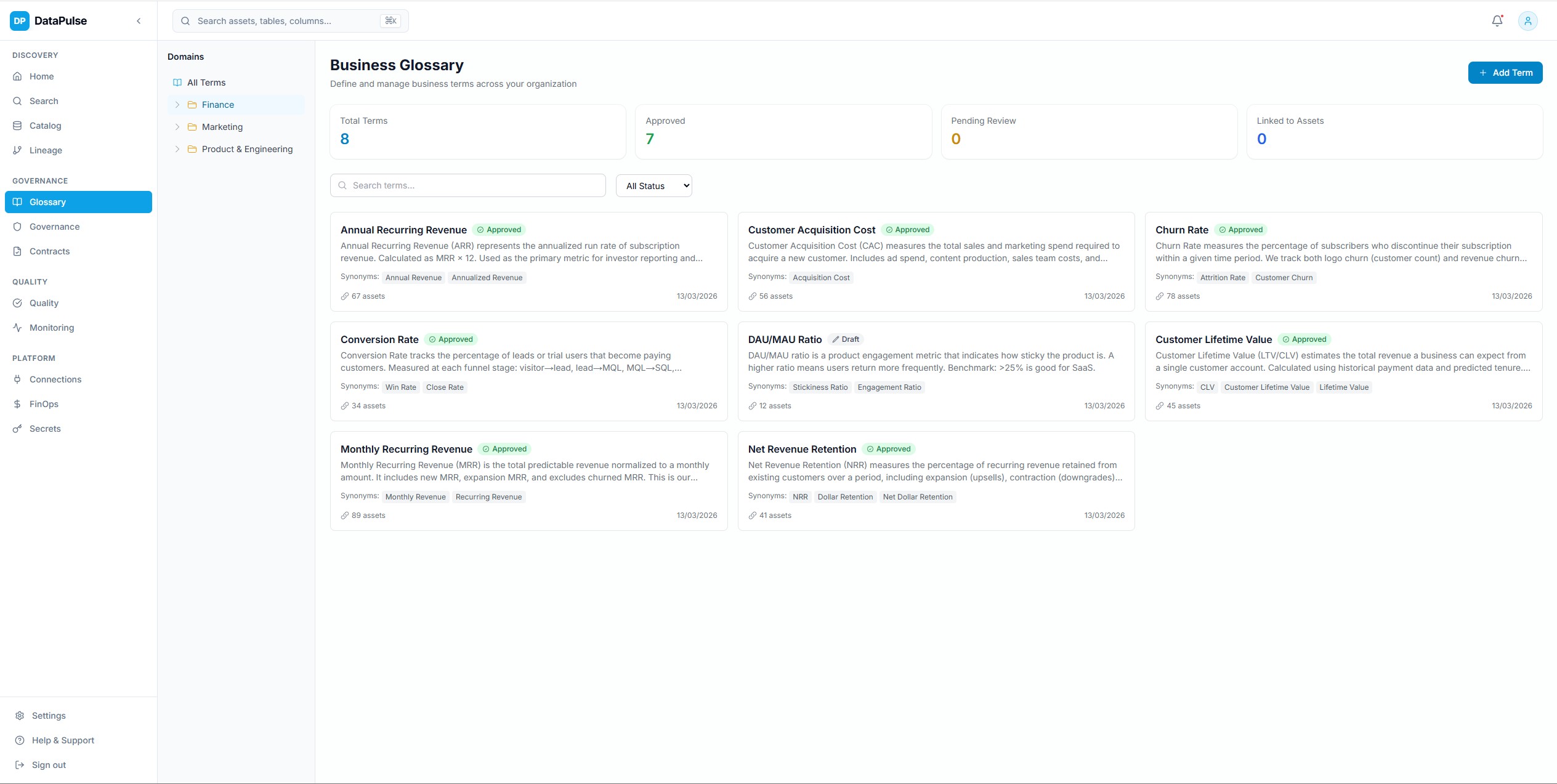
Glossaire metier
Glossaire metier centralise avec definitions de termes, propriete par domaine et liaison aux actifs. Etablit le pont entre le langage metier et les metadonnees techniques.
Stack technique
Construit avec
Framework
Data
AI
UI
Infra
Langages
Python 3.11TypeScriptSQLGraphQLYAMLCypherDockerfileCe que ce projet démontre