
Comply-Agent
Une plateforme de conformité pilotée par l'IA qui transforme l'analyse réglementaire en système opérationnel traçable, plutôt qu'en exercice de consulting documentaire.
Démo frontend, l'infrastructure backend n'est pas déployée pour cette vitrine
Résultats clés
Cycle d'évaluation
Semaines -> heures
Le produit compresse la revue manuelle des contrôles en un workflow numérique guidé.
Couverture réglementaire
2 réglementations clés
NIS2 et DORA sont cartographiés en contrôles structurés et analyses étayées par des preuves.
Profondeur opérationnelle
16 tâches en arrière-plan
Le traitement de documents, l'analyse IA, la génération de rapports et le monitoring sont distribués de manière asynchrone.
Couches d'observabilité
3 vues empilées
Sentry, Prometheus/Grafana et Langfuse tracent le produit de l'infrastructure jusqu'au comportement IA au niveau des tokens.
Le problème
Ce que ce projet devait résoudre
Le travail de conformité réglementaire est généralement dispersé entre tableurs, fichiers de politique, entretiens manuels et présentations de consulting génériques. Comply-Agent a reformulé ce processus comme un workflow produit avec preuves, notation et remédiation centralisés.
Comply-Agent a été conçu pour les organisations confrontées aux exigences NIS2 et DORA sans le temps ni la structure interne pour mener des audits manuels lourds. Le produit combine ingestion de documents, recherche sémantique, analyse par IA et suivi de progression dans un workflow qui rend la conformité visible, structurée et actionnable.
Le backend repose sur FastAPI avec une architecture de services asynchrone, PostgreSQL pour les données structurées, Qdrant pour la recherche vectorielle, Redis et Celery pour l'exécution en arrière-plan, et une couche LLM sécurisée construite avec PydanticAI. Le frontend traduit cette complexité en une expérience pilotée par des tableaux de bord, avec un onboarding guidé, une analyse par contrôle et un assistant ancré dans les preuves téléversées.
Ce qui rend le projet crédible n'est pas uniquement la couche IA. C'est la posture opérationnelle qui l'entoure : défenses contre l'injection de prompts, pistes d'audit, observabilité via Langfuse et OpenTelemetry, et monitoring d'infrastructure sur l'ensemble de la stack. L'objectif était de construire un outil auquel les équipes pouvaient faire confiance, pas seulement une démo.
Ce qui a changé
Au lieu de traiter la conformité comme un livrable de consulting qui devient obsolète dès sa remise, le produit la transforme en système vivant : téléverser des preuves, classifier l'exposition, analyser les contrôles, examiner les écarts et suivre la remédiation depuis une surface de commande unique.
Pourquoi c'était difficile
La difficulté ne résidait pas dans la production de réponses. Elle était dans l'ingénierie de la confiance autour de ces réponses : qualité de la recherche sémantique, chemins de surcharge humaine, disjoncteurs, discipline de file d'attente, et suffisamment de télémétrie pour expliquer pourquoi le système a répondu de telle manière sous charge réelle.
Contraintes
- Le système devait protéger la propriété intellectuelle tout en démontrant publiquement sa profondeur technique.
- Les réponses de l'IA devaient être ancrées, vérifiables et auditables plutôt que convaincantes mais invérifiables.
- Le traitement intensif de documents et l'analyse de contrôles devaient s'exécuter sans bloquer l'expérience produit.
Mon rôle
- Définition de l'architecture produit, du modèle de données à la topologie de déploiement.
- Structuration du pipeline d'ingestion, de recherche et d'analyse à travers FastAPI, Celery, PostgreSQL, Qdrant et Redis.
- Conception du tableau de bord, de l'assistant et des flux de revue pour une utilisabilité de niveau analyste.
- Mise en place des patterns d'observabilité et de sécurité pour que la couche IA puisse être déboguée et approuvée en production.
Preuves
À quoi ressemble réellement le produit
Captures d'écran réelles du produit, chacune illustre un argument concret de clarté, de contrôle ou d'observabilité.
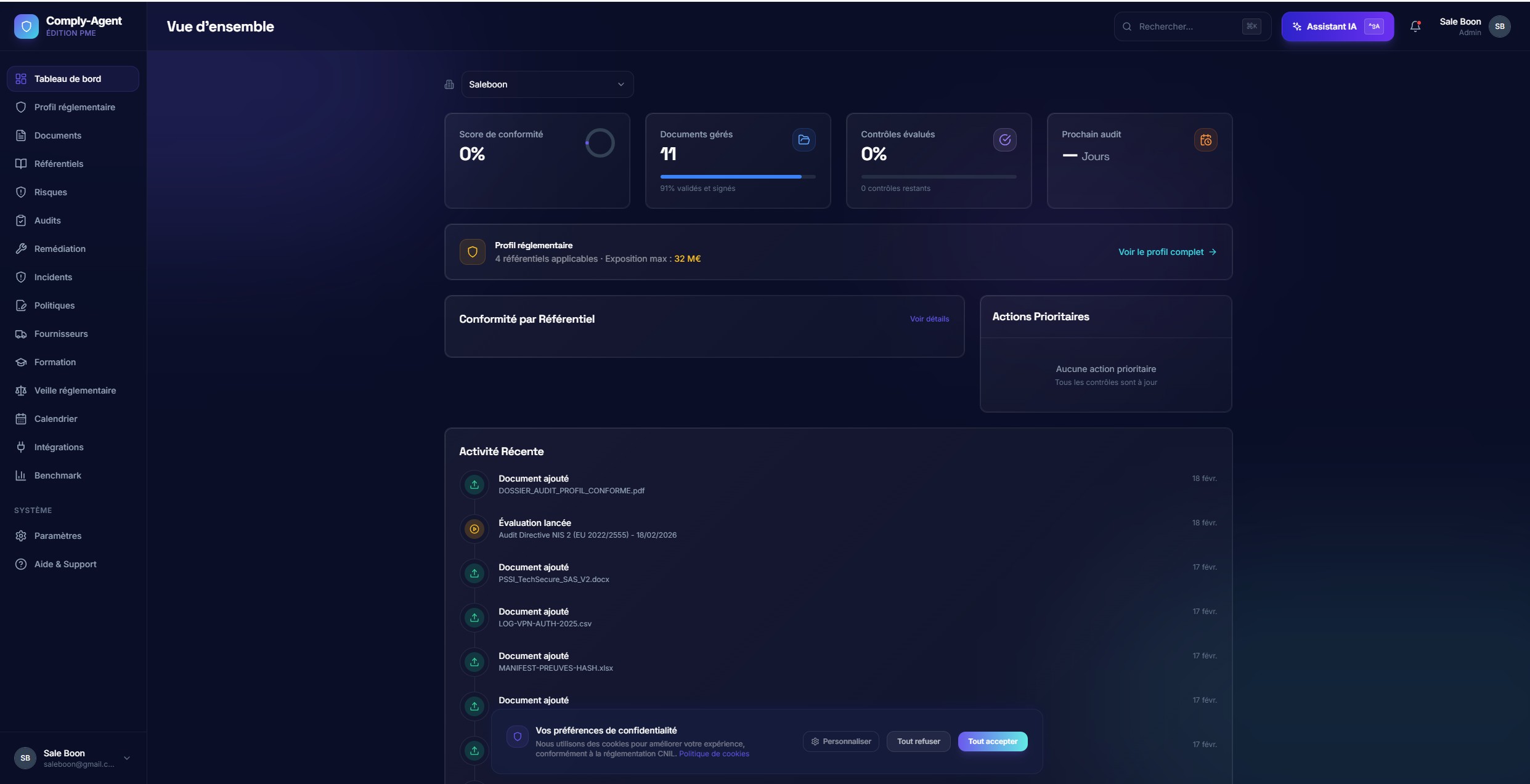 Command CenterCliquer pour agrandir
Command CenterCliquer pour agrandirSurface de commande conformité
Un tableau de bord qui répond d'abord aux questions opérationnelles : où en sommes-nous, qu'est-ce qui a changé, et quelle action mener ensuite.
Le produit met en avant les décisions et la remédiation, pas un mur de contenu réglementaire statique.
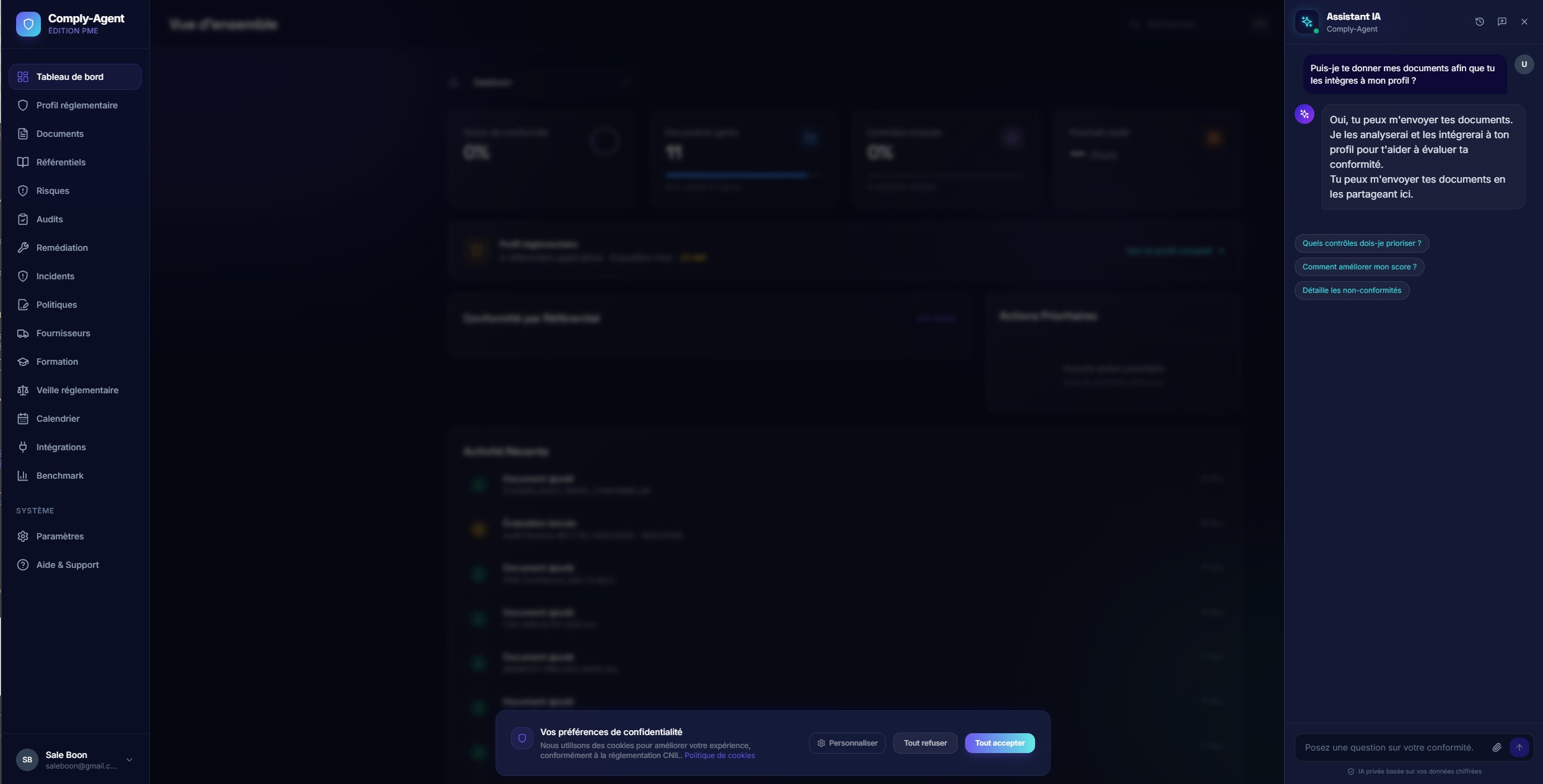 Moteur de preuvesCliquer pour agrandir
Moteur de preuvesCliquer pour agrandirAssistant IA ancré
L'assistant génère ses réponses à partir des documents de l'entreprise et suggère des approfondissements au lieu de se comporter comme un chatbot sans limites.
La qualité de la recherche et le cadrage des réponses ont été conçus pour soutenir la confiance, pas la nouveauté.
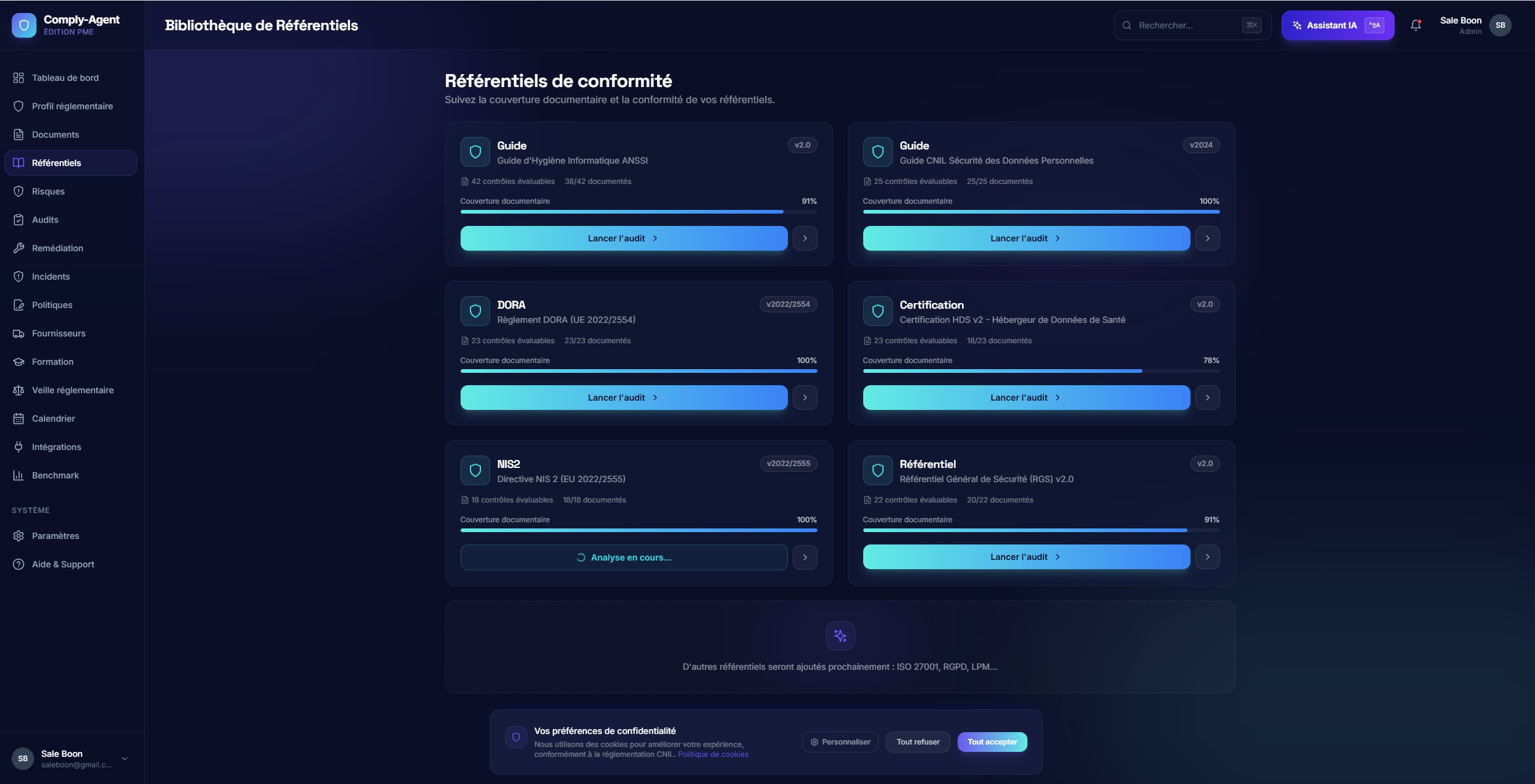 Workflow analysteCliquer pour agrandir
Workflow analysteCliquer pour agrandirRevue contrôle par contrôle
Les évaluations par contrôle exposent les preuves, le statut et les chemins de surcharge pour que le réviseur humain garde le contrôle.
C'est là que la sortie IA devient opérationnellement utile : structurée, vérifiable et actionnable.
 Couche de preuveCliquer pour agrandir
Couche de preuveCliquer pour agrandirVisibilité des traces LLM
Chaque génération est observable via les traces, la latence, l'utilisation de tokens et les informations de routage.
La couche d'observabilité accélère les itérations et rend le comportement du modèle débogable.
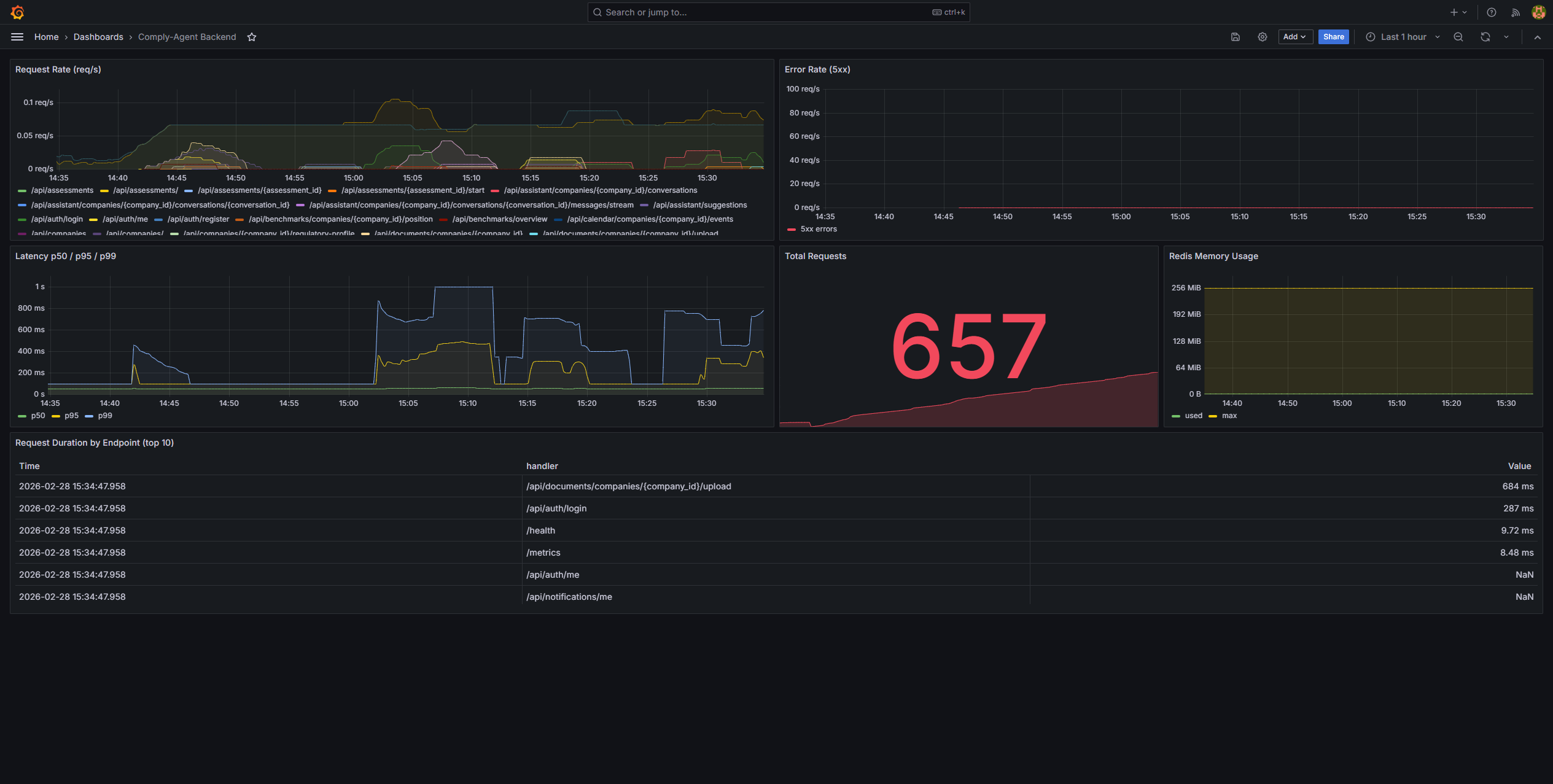 Signal OpsCliquer pour agrandir
Signal OpsCliquer pour agrandirSanté de l'infrastructure
La santé de l'API, des workers, de la base de données et du cache est visible en parallèle de l'expérience produit.
Les fonctionnalités IA ont été traitées comme des systèmes de production dès le premier jour, pas comme des ornements de démonstration.
Décisions
Les compromis qui ont façonné le produit
Le travail le plus solide se révèle dans les choix faits sous pression, pas seulement dans l'interface finale.
Recherche hybride plutôt que similarité naïve
Défi
Les documents de conformité sont longs, bruités, multilingues et remplis de preuves quasi-dupliquées.
Décision
La couche de recherche combine l'expansion multi-requêtes, HyDE et le reclassement avant l'analyse.
Compromis
Cela ajoute de l'orchestration et de la latence, mais améliore nettement la pertinence des preuves et la qualité des réponses.
Maillage de tâches asynchrones plutôt que traitement lié aux requêtes
Défi
Le parsing, le découpage, l'embedding et la génération de rapports sont trop coûteux pour être liés directement aux requêtes utilisateur.
Décision
Le traitement des documents et des analyses a été déplacé dans des pipelines en arrière-plan pilotés par Celery avec coordination Redis.
Compromis
La complexité opérationnelle augmente, mais l'expérience utilisateur reste réactive et le système passe mieux à l'échelle.
Observabilité avant mise à l'échelle
Défi
Les systèmes LLM deviennent coûteux et opaques très rapidement lorsque l'instrumentation arrive trop tard.
Décision
Le traçage, les métriques et le monitoring d'erreurs ont été traités comme des fonctionnalités produit essentielles, pas comme des extras de déploiement.
Compromis
Le coût de mise en place est plus élevé au départ, mais le débogage et la confiance s'améliorent considérablement avec la croissance de l'usage.
Architecture
Comment les données circulent dans le système
Ingestion
Les utilisateurs téléversent des fichiers de politique, des preuves d'audit et des documents opérationnels dans un flux d'intake structuré.
→ Le produit part de preuves réelles de l'entreprise plutôt que de questionnaires génériques.
Parsing + découpage
Docling et les tâches en arrière-plan normalisent les fichiers, extraient la structure et préparent des chunks sémantiquement exploitables.
→ Les sources brutes deviennent prêtes pour la recherche sans bloquer l'interface.
Indexation + recherche
Les embeddings sont stockés dans Qdrant et combinés avec le filtrage par métadonnées et le reclassement lors de la recherche.
→ Les preuves pertinentes peuvent être extraites rapidement et défendues lors de la revue.
Analyse des contrôles
PydanticAI orchestre le raisonnement au niveau des contrôles avec des vérifications de sécurité, du routage et un formatage de sortie compatible avec l'audit.
→ Les évaluations deviennent des sorties produit structurées et explicables plutôt que du texte de modèle opaque.
Exploitation + monitoring
Les tableaux de bord, les flux d'assistant et les surfaces d'observabilité exposent l'état du produit, le comportement de l'IA et la santé de l'infrastructure.
→ Les équipes peuvent agir sur le système et faire confiance à son fonctionnement en conditions de production.
Comply-Agent utilise un monolithe en couches côté backend : les routes FastAPI délèguent aux services, les services coordonnent les repositories à travers PostgreSQL, Qdrant et Redis, et Celery gère le travail asynchrone intensif. Le frontend est une application Next.js pilotée par des tableaux de bord qui expose le système comme une surface opérationnelle guidée plutôt qu'une expérience de chat IA générique.
Surfaces produit
Les interfaces qui portent l'expérience
Tableau de bord conformité
Une surface de commande pour la progression des référentiels, les contrôles non conformes et les actions prioritaires.
Assistant IA de conformité
Un assistant ancré qui répond à partir des preuves téléversées et diffuse les réponses en streaming dans un format adapté à la revue.
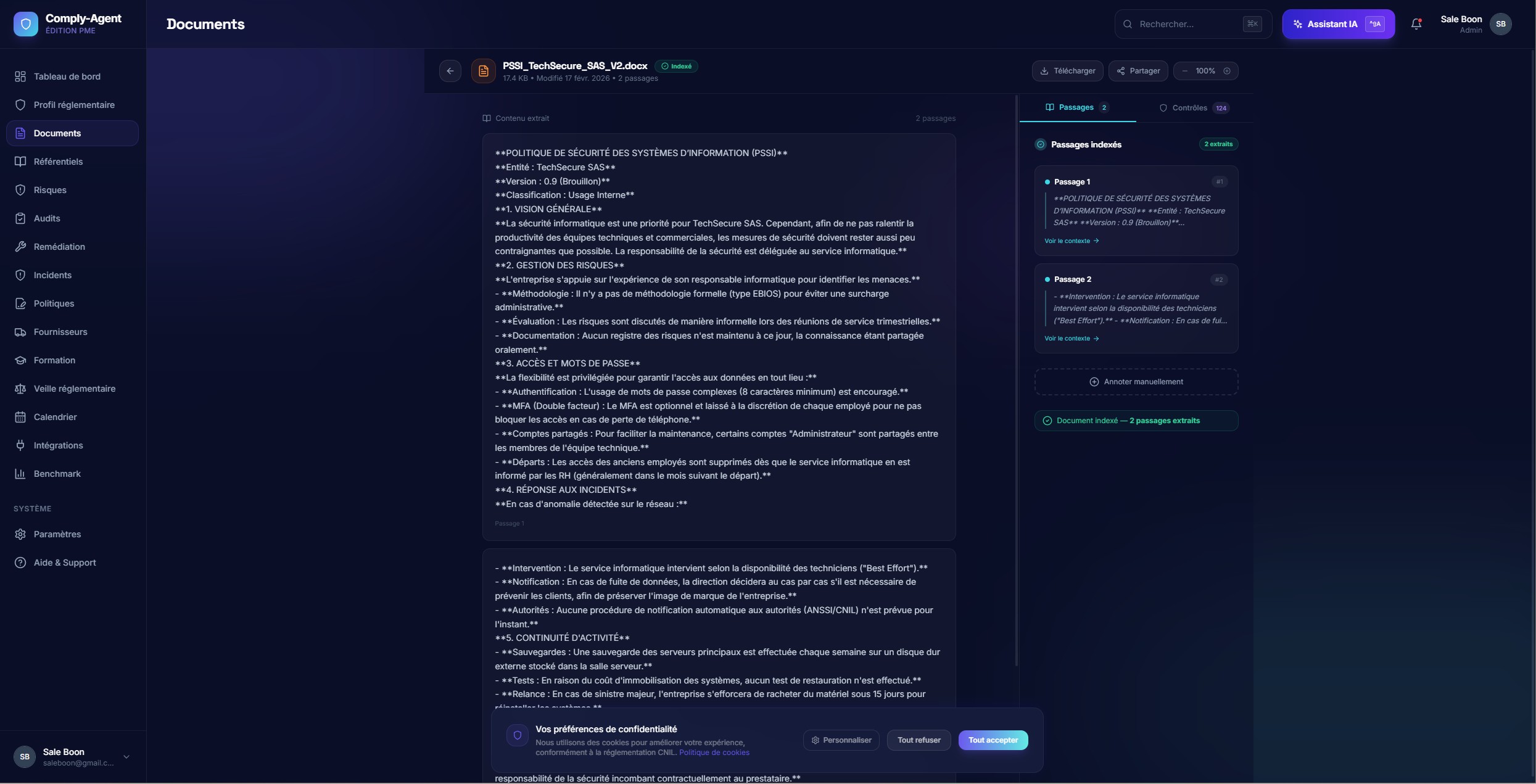
Pipeline d'intelligence documentaire
Un flux d'ingestion et d'indexation de bout en bout qui transforme des fichiers sources denses en connaissances prêtes pour la recherche.
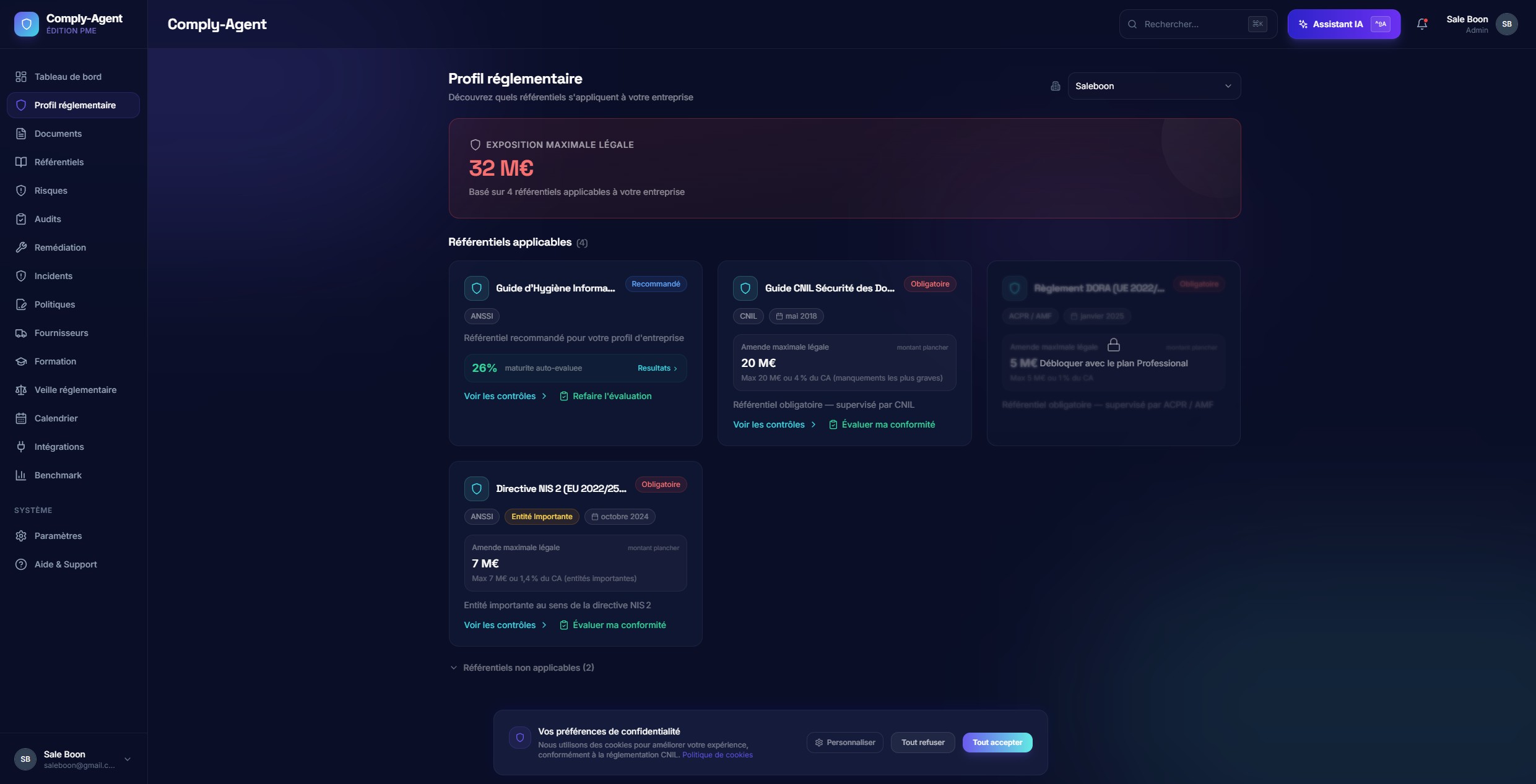
Profil réglementaire
Une couche de classification qui identifie l'exposition réglementaire, les référentiels applicables et le contexte de risque.
Référentiel et analyse des contrôles
La surface d'analyse où la notation étayée par des preuves, la détection d'écarts et les workflows de surcharge se rejoignent.
Observabilité LLM
Visibilité au niveau des traces pour l'utilisation des modèles, les coûts, la latence et les décisions de routage sur la couche assistant.
Monitoring d'infrastructure
Des tableaux de bord de production couvrent les performances de l'API, les workers, la santé de la base de données et le comportement du cache.
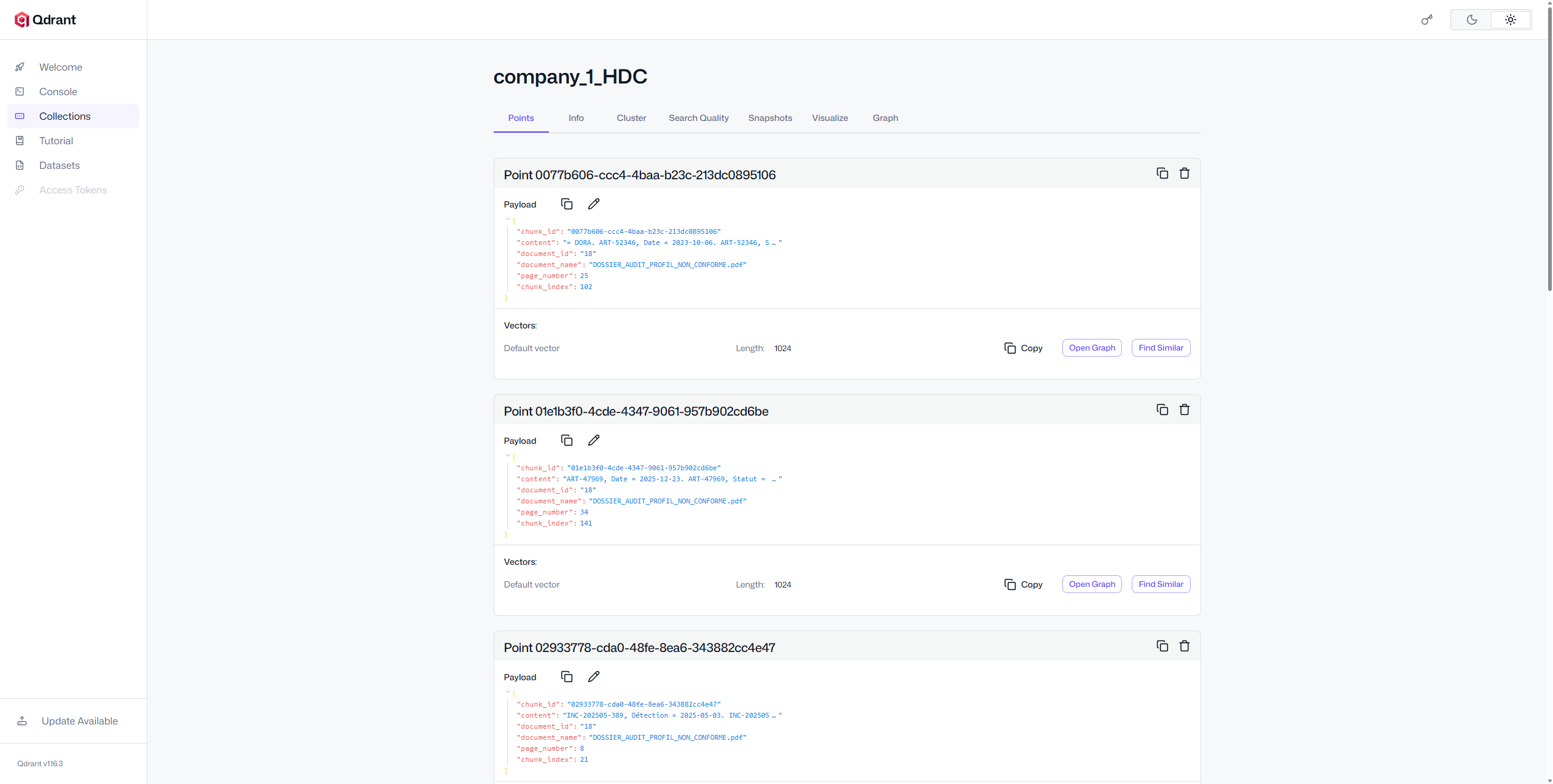
Moteur de recherche vectorielle
Une couche de recherche sémantique qui alimente les réponses ancrées et la collecte de preuves au niveau des contrôles.
Stack technique
Construit avec
FastAPI
Framework API backend
PostgreSQL
Base de données relationnelle principale
Redis
Cache, broker et limitation de débit
Celery
File de tâches distribuée
Qdrant
Base de données vectorielle pour le RAG
Mistral AI
Fournisseur d'inférence LLM
Langfuse
Observabilité LLM
Grafana
Tableaux de bord d'infrastructure
Prometheus
Collecte de métriques
Framework
UI
Data
AI
Infra
Langages
TypeScriptPythonSQLCSS/TailwindCe que ce projet démontre