
DataPulse
An open-source enterprise data management suite — catalog, column-level lineage, pipeline monitoring, FinOps, secrets management, and governance with 14+ scanner integrations across Snowflake, dbt, Azure Data Factory, Power BI, and more.
Platform scanners
14+ integrations
Snowflake, dbt, ADF, Power BI, Databricks, BigQuery, Airflow, Fivetran, Kafka, Looker, Tableau, PostgreSQL, MySQL, Synapse.
Backend scale
248 Python files
56+ service classes, 36 API route modules, 40+ database models, full async stack.
Enterprise auth
SAML + SCIM + SSO
Azure AD, Okta, Google OAuth, SAML 2.0 with SCIM 2.0 provisioning and row-level security.
Infrastructure
6 Docker services
PostgreSQL, Redis, OpenSearch, FastAPI, ARQ workers, Next.js — with Kubernetes Helm charts for production.
The Problem
What this project had to solve
Enterprise data teams are blind to their own data ecosystem. Metadata is scattered across Snowflake, dbt, ADF, Power BI, and a dozen other tools. Nobody knows which pipelines feed which dashboards, how much Snowflake costs per team, when secrets expire, or whether data quality is degrading. Existing tools like Purview are expensive, rigid, and opaque.
DataPulse started from a real pain point: enterprise data teams rely on expensive, opaque tools like Microsoft Purview to understand what data they have, where it flows, and how much it costs. The goal was to build a production-grade open-source alternative that gives data teams full visibility into their data ecosystem.
The platform is a full-stack application with a FastAPI async backend orchestrating 14+ scanner plugins that crawl metadata from Snowflake, dbt, Azure Data Factory, Power BI, Databricks, BigQuery, Airflow, and more. Each scanner follows a decorator-based registration pattern, making the framework extensible. A Neo4j-style knowledge graph in PostgreSQL with OpenSearch powers full-text discovery across the entire catalog.
The frontend is a Next.js 14 application with D3.js-powered lineage graphs, Recharts analytics dashboards, and enterprise features like SAML SSO, SCIM provisioning, and row-level security. The result is a platform that replaces a $500K+ Purview deployment with something data teams can actually extend and own.
What changed
Instead of paying $500K+ for Purview and still not seeing column-level lineage or FinOps attribution, teams get a platform they can deploy in Docker Compose, extend with custom scanners, and operate with full enterprise security — all open-source.
Why it was hard
The core challenge was building a unified metadata model that normalizes wildly different APIs — Snowflake's INFORMATION_SCHEMA, dbt's manifest.json, ADF's activity runs, Power BI's REST API — into a single queryable catalog with cross-platform lineage. Each scanner speaks a different language, and the system had to correlate them into coherent data flows.
Constraints
- 14+ platform scanners needed a common plugin architecture — each with wildly different APIs and metadata models.
- Column-level lineage had to work across SQL, dbt manifest.json, and ADF activity definitions — each expressing transformations differently.
- Multi-tenant isolation required PostgreSQL Row-Level Security with zero performance compromise on catalog queries.
- Enterprise SSO (SAML 2.0, SCIM 2.0, Azure AD, Okta) had to work alongside simple JWT auth for smaller teams.
- FinOps cost normalization across Snowflake warehouses and Azure resources needed configurable attribution rules.
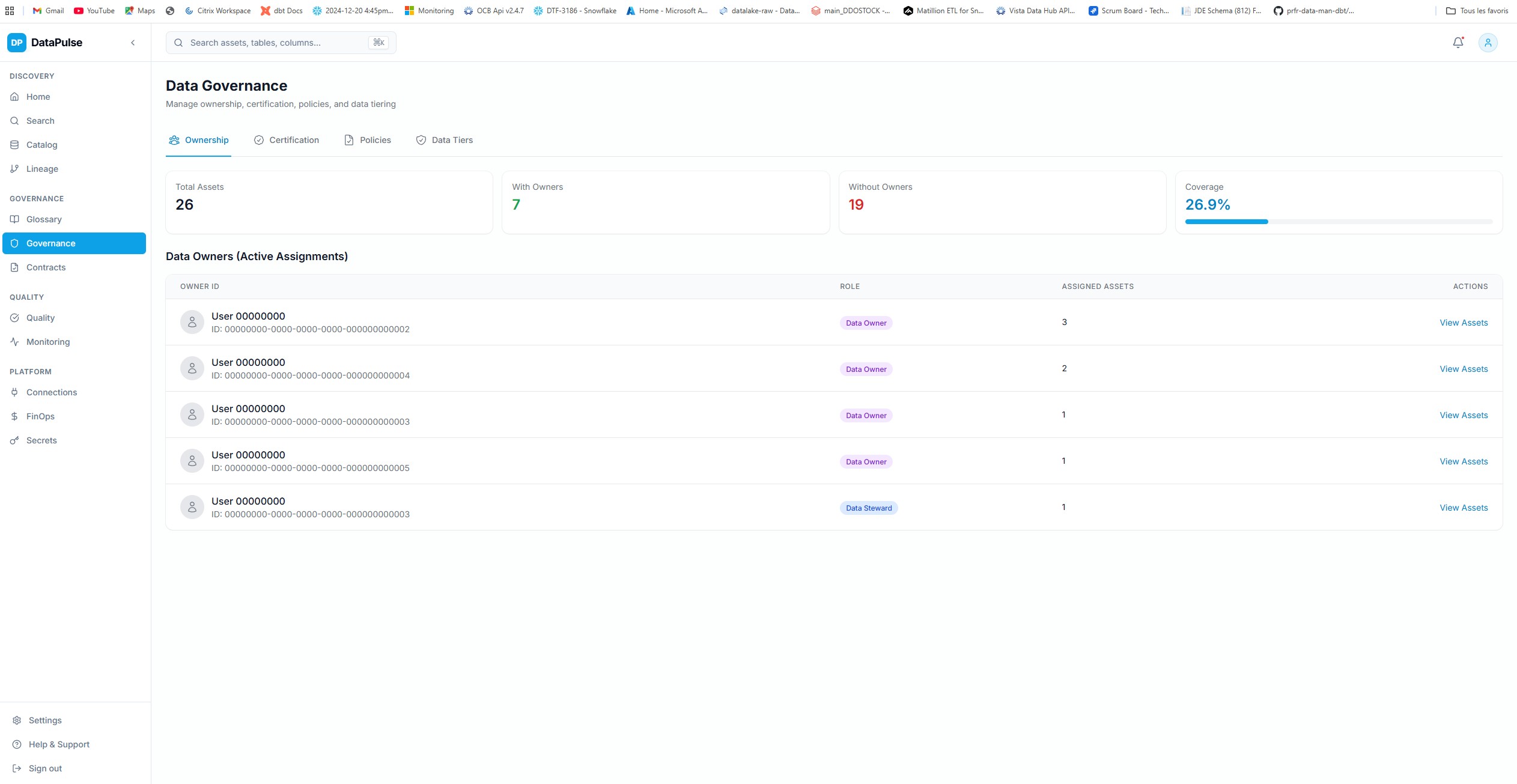
My role
- Designed and built the full-stack platform: FastAPI backend (248 Python files), Next.js frontend (131 TSX files), Docker infrastructure.
- Architected the plugin-based scanner framework with decorator registration for 14+ platform integrations.
- Built column-level lineage tracking with 9 transformation types and confidence scoring.
- Implemented enterprise auth stack: SAML 2.0, SCIM 2.0, Azure AD, Okta, JWT, API keys.
- Designed the FinOps module with cost attribution, anomaly detection, and budget alerting.
- Built the secrets management system with risk scoring and dependency mapping.
Proof
What the product actually looks like
Real screens from the product — each one supports a specific argument about clarity, control, or observability.
 DiscoveryClick to view full size
DiscoveryClick to view full sizeData Catalog Explorer
Unified catalog view with asset hierarchy, metadata enrichment, tagging, and full-text search powered by OpenSearch across all connected platforms.
Assets from 14+ platforms are normalized into a single browsable hierarchy — database → schema → table → column.
 Cost IntelligenceClick to view full size
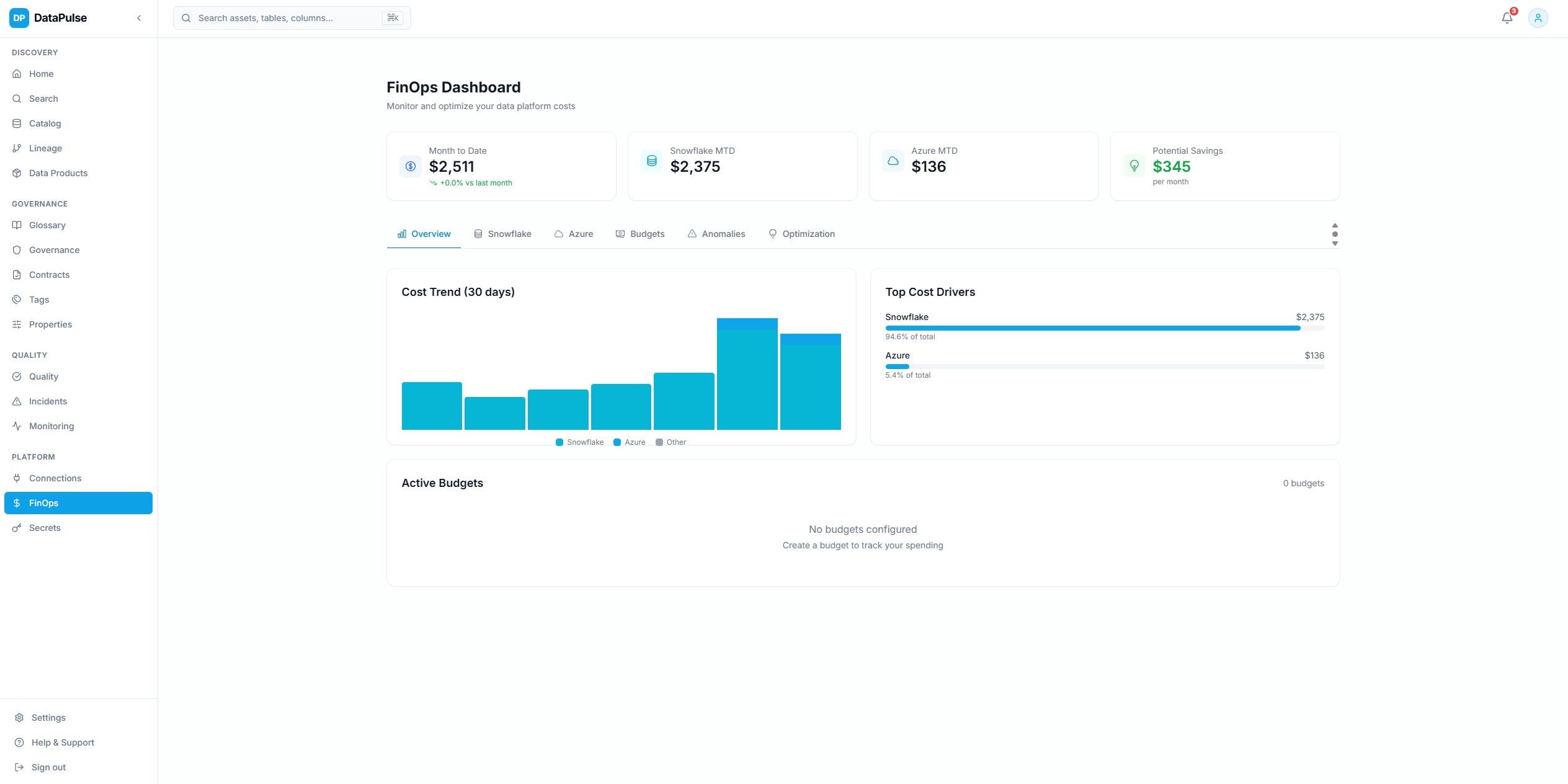
Cost IntelligenceClick to view full sizeFinOps Dashboard
Unified cost visibility across Snowflake warehouses and Azure resources with trend analysis, budget tracking, and team-level attribution.
Cost normalization and attribution rules let teams understand exactly where spend is going and why.
 Operational HealthClick to view full size
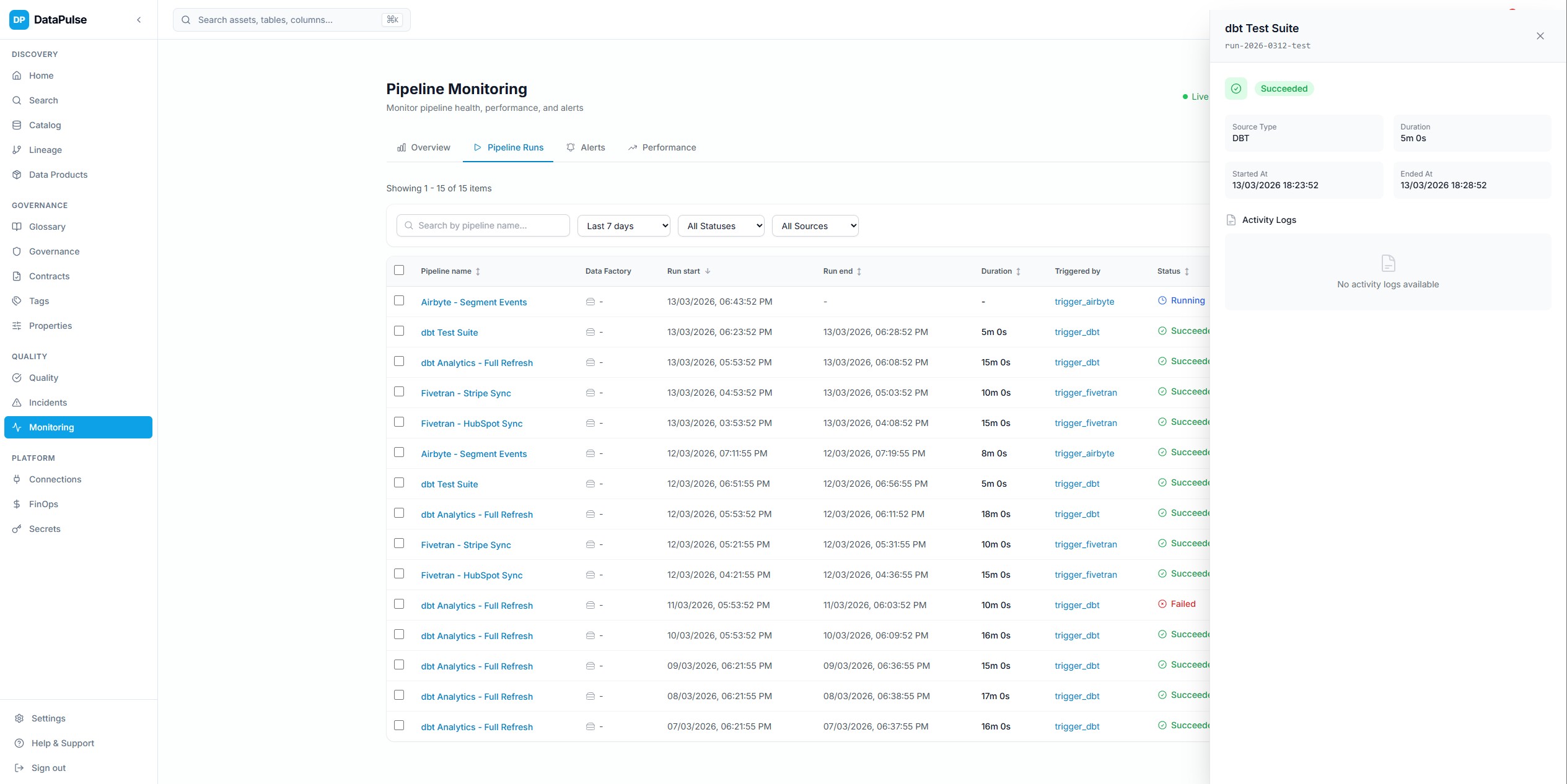
Operational HealthClick to view full sizePipeline Monitoring
Real-time pipeline run tracking with status aggregation, SLA monitoring, alert rules, and historical trend analysis.
Run collectors for ADF, dbt Cloud, and Snowflake tasks feed into a unified monitoring surface with configurable alerts.
 ComplianceClick to view full size
ComplianceClick to view full sizeGovernance & Policies
Data governance with classification policies, retention rules, column-level security, and certification workflows.
Built for enterprise compliance — data classification, access policies, and audit trails in one place.
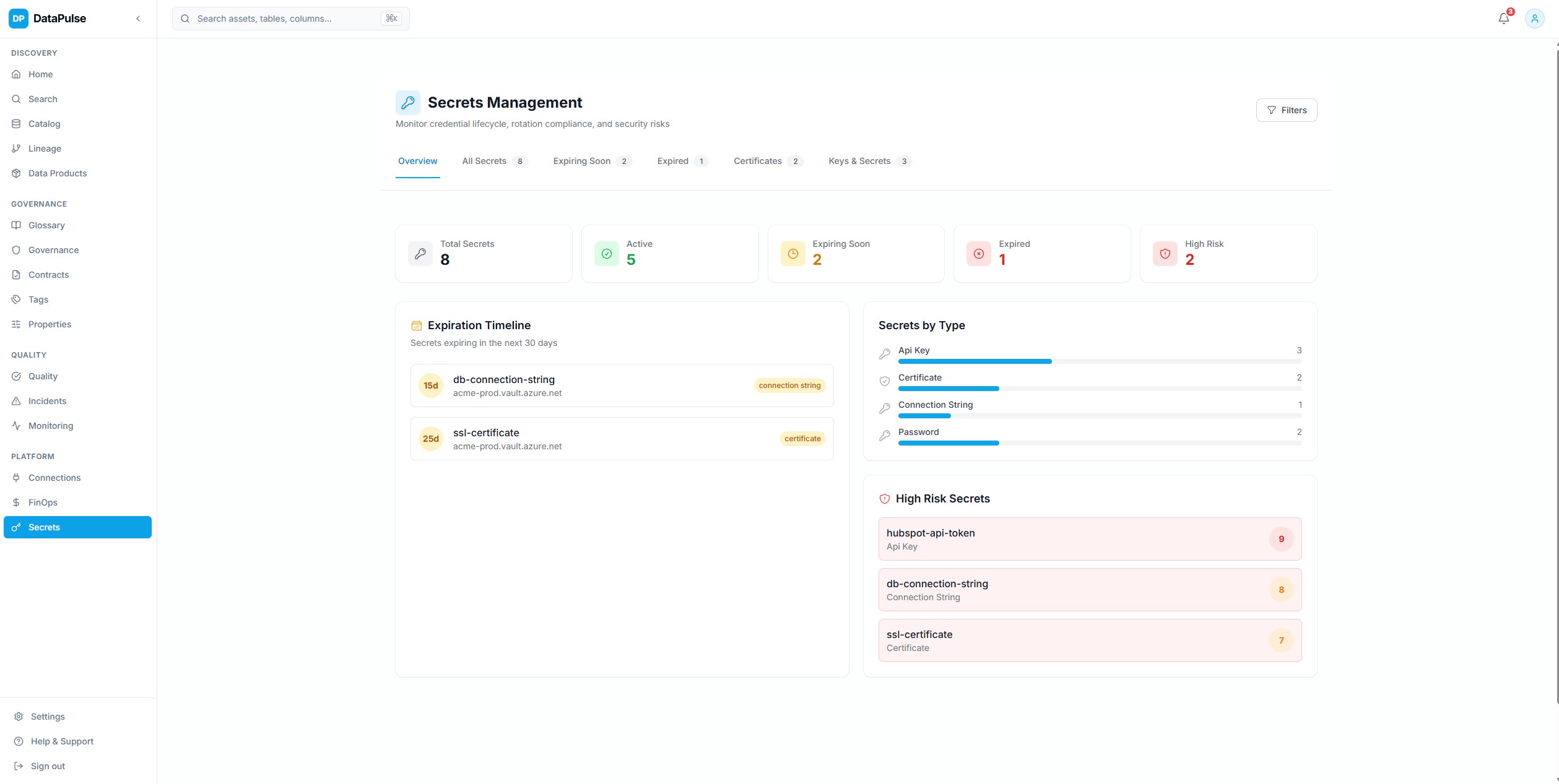 SecurityClick to view full size
SecurityClick to view full sizeSecrets Management
Secret lifecycle tracking with risk scoring, expiration alerts, rotation history, and dependency mapping to downstream pipelines.
13 secret types tracked with ML-based risk scoring — the system knows which secrets are about to expire and what breaks if they do.
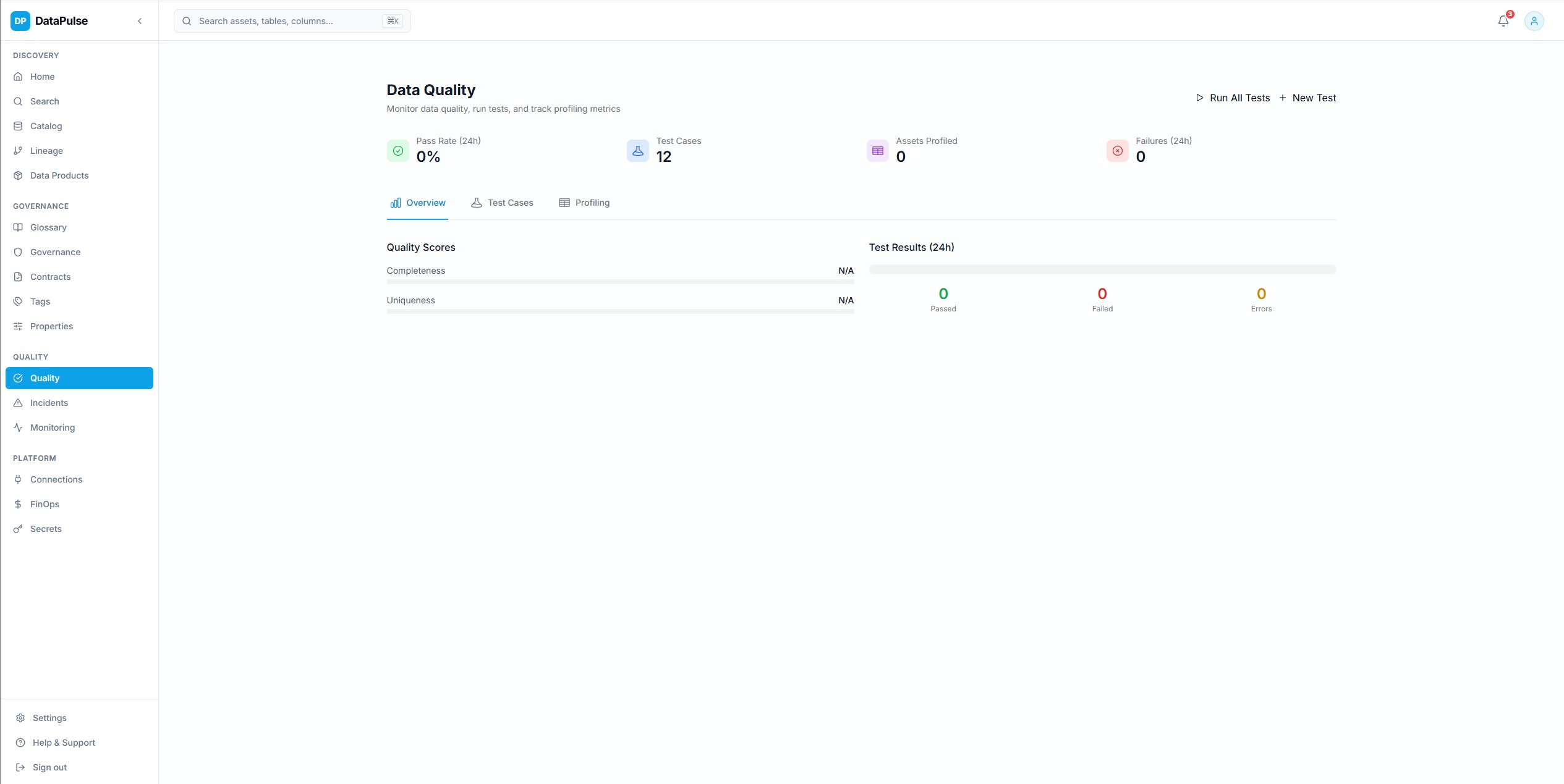 QualityClick to view full size
QualityClick to view full sizeData Quality Profiling
Statistical profiling with Soda Core integration, quality scoring per asset, PII detection, and anomaly identification using scikit-learn.
Quality scores roll up from column-level assertions to table-level KPIs, giving teams a clear health signal.
Decisions
Tradeoffs that shaped the product
The strongest work is visible in the choices made under pressure, not just in the final interface.
Plugin-based scanner architecture
Challenge
14+ platforms each expose metadata through completely different APIs — REST, SQL, manifest files, SDKs. Hardcoding each one would create an unmaintainable monolith.
Decision
Built a decorator-based plugin framework where each scanner registers capabilities (@metadata_scanner, @cost_collector, @run_collector). Abstract base classes define the contract, and new platforms can be added without touching core code.
Tradeoff
The abstraction layer added upfront complexity but made the difference between 'one more scanner' being a 2-day task vs. a 2-week refactor.
PostgreSQL RLS over application-level tenancy
Challenge
Multi-tenant SaaS needed ironclad data isolation. Application-level WHERE clauses are error-prone — one missed filter leaks data across tenants.
Decision
Implemented PostgreSQL Row-Level Security policies that enforce tenant isolation at the database level. Even if application code has a bug, the database won't return another tenant's data.
Tradeoff
RLS added migration complexity and required careful session-level tenant context management, but the security guarantee is worth it for enterprise customers.
OpenSearch alongside PostgreSQL
Challenge
Catalog search needs to be fast, fuzzy, and faceted. PostgreSQL full-text search works but doesn't scale well for complex faceted queries across millions of assets.
Decision
Added OpenSearch as a dedicated search layer synced from PostgreSQL. Catalog mutations write to both stores, and search queries hit OpenSearch with faceted filtering while detail views hit PostgreSQL.
Tradeoff
Dual-write adds operational overhead (another stateful service) but search performance went from seconds to milliseconds with proper relevance ranking.
Architecture
How data flows through the system
Connection & Scanner Registration
Data team registers platform connections (Snowflake credentials, dbt Cloud tokens, ADF service principals). Each connection activates the matching scanner plugins via the decorator-based framework.
→ Authenticated connections to 14+ platforms ready for metadata extraction.
Metadata Scanning & Ingestion
ARQ background workers execute scanners on schedule. Each scanner crawls its platform's metadata (tables, columns, pipelines, dashboards) and normalizes output into the unified asset model with qualified naming conventions.
→ Normalized metadata catalog with consistent asset hierarchy across all platforms.
Lineage Extraction & Correlation
Lineage scanners parse SQL queries (Snowflake ACCESS_HISTORY), dbt manifest.json, and ADF activity definitions to extract column-level data flows. Relationships are correlated across platforms with confidence scoring.
→ Cross-platform column-level lineage graph with 9 transformation types and impact analysis.
Quality Profiling & Classification
Soda Core profiles data statistics per table and column. scikit-learn classifies sensitive data (PII detection). Quality scores roll up from assertions to asset-level KPIs.
→ Per-asset quality scores, PII flags, and anomaly detection feeding governance workflows.
Cost Collection & Attribution
Cost collectors pull Snowflake warehouse usage and Azure resource costs. Normalization rules convert to USD. Attribution rules map costs to teams, projects, and pipelines via tags.
→ Unified FinOps view with budget alerts, anomaly detection, and team-level cost attribution.
Search, Governance & Delivery
OpenSearch indexes the full catalog for sub-second fuzzy search. Governance policies enforce classification, retention, and access controls. SAML SSO and SCIM provisioning handle enterprise identity.
→ Production-ready data platform with enterprise auth, governance, and instant discovery.
DataPulse is a 6-service Docker Compose stack with a FastAPI async backend (248 Python files, 56+ services) orchestrating 14+ platform scanners via a decorator-based plugin framework. ARQ workers handle background scanning, with results normalized into PostgreSQL (with RLS for multi-tenancy) and synced to OpenSearch for sub-second catalog search. The frontend is a Next.js 14 application with D3.js lineage graphs, Recharts dashboards, and TanStack Table for data-dense views. Enterprise auth supports SAML 2.0, SCIM 2.0, Azure AD, Okta, and Google OAuth alongside JWT. Kubernetes Helm charts and Terraform modules handle production deployment with horizontal pod autoscaling.
Product surfaces
The interfaces that carry the experience
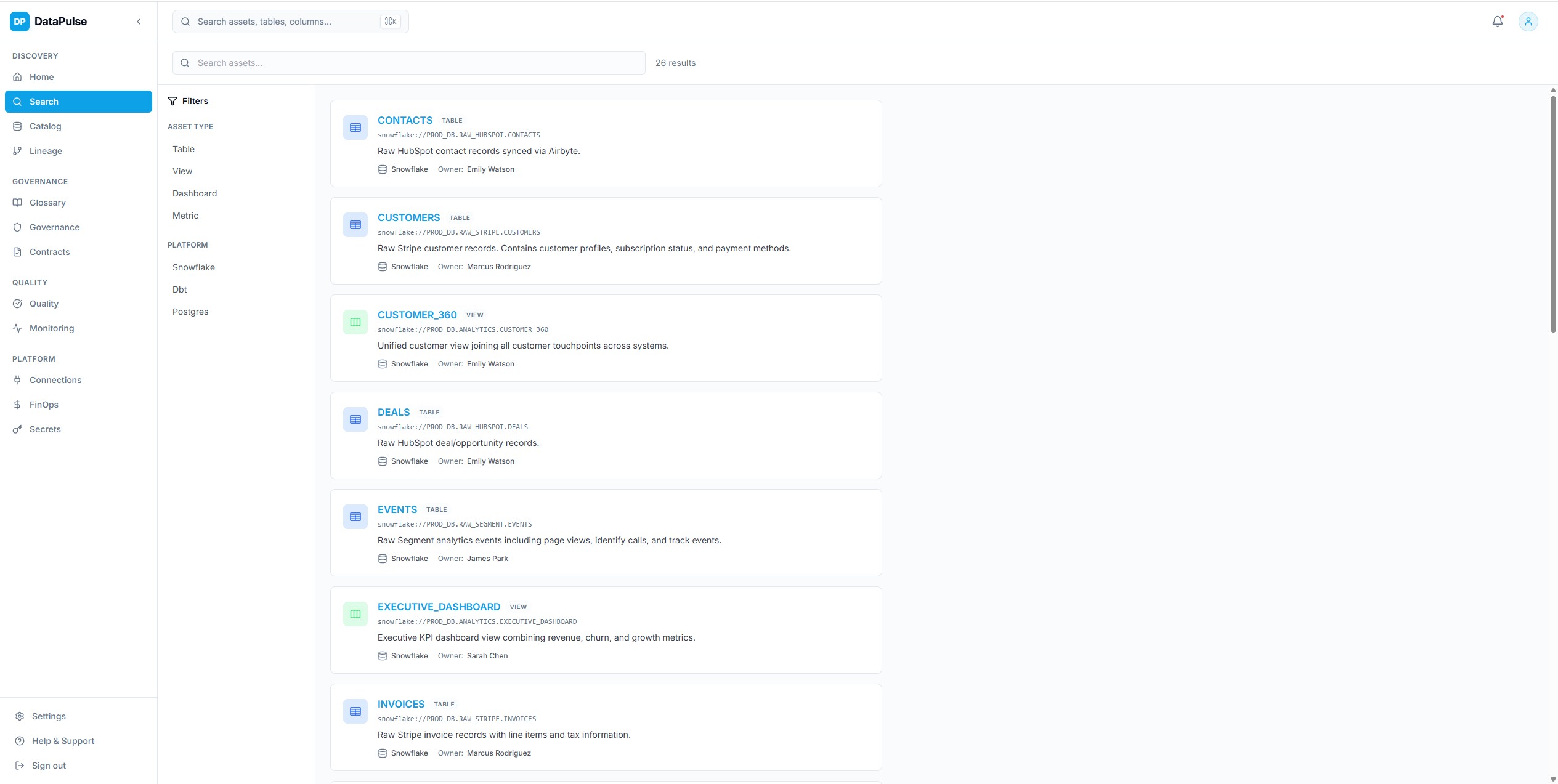
Universal Search & Discovery
Full-text search across the entire data catalog powered by OpenSearch — fuzzy matching, faceted filtering by platform, type, owner, tags, and classification. Designed to answer 'where is this data?' in seconds.
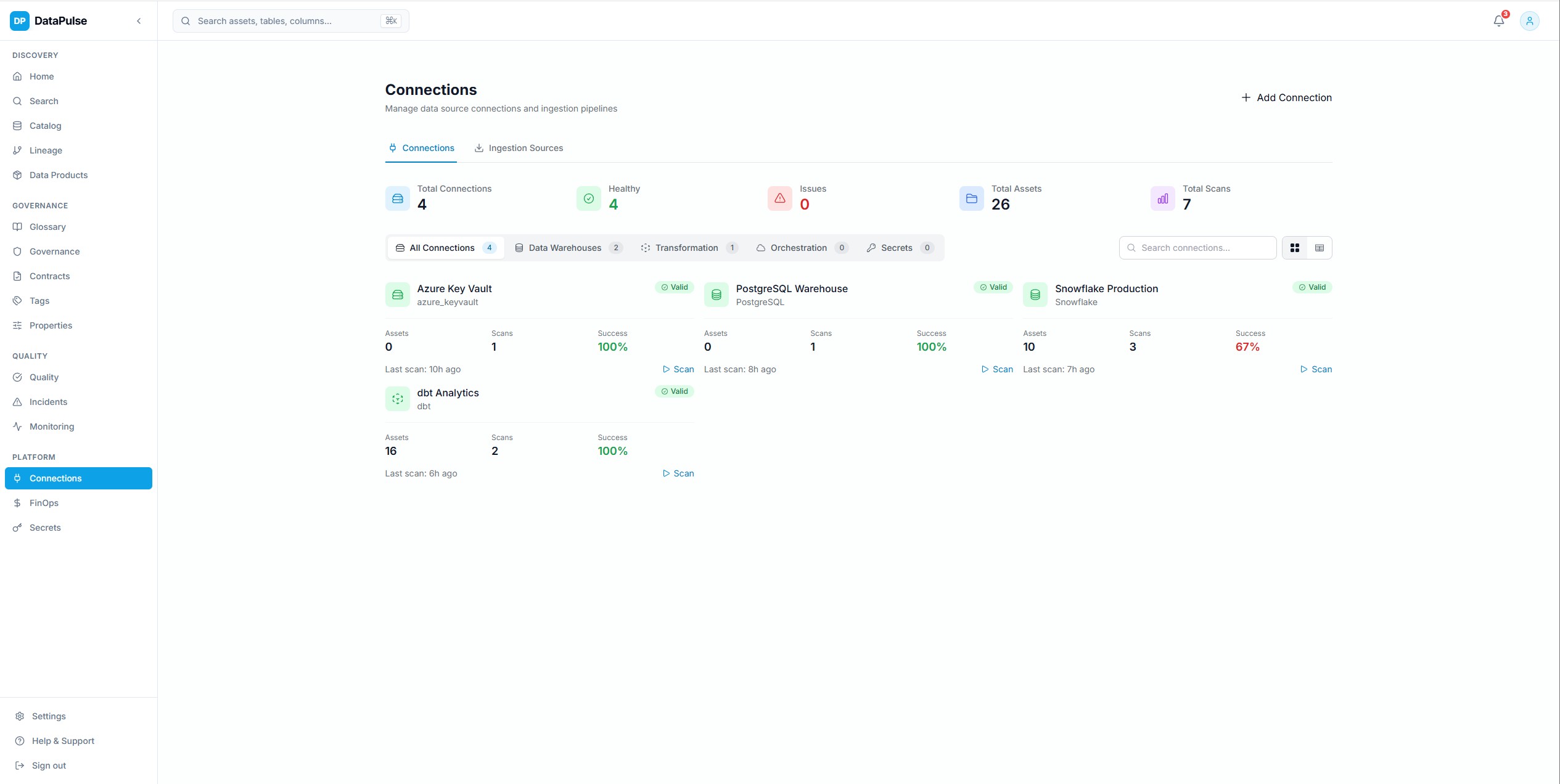
Connection Management
Register and manage connections to all supported platforms with encrypted credential storage, health monitoring, and automatic scanner activation. Supports Azure Key Vault, service principals, and API tokens.
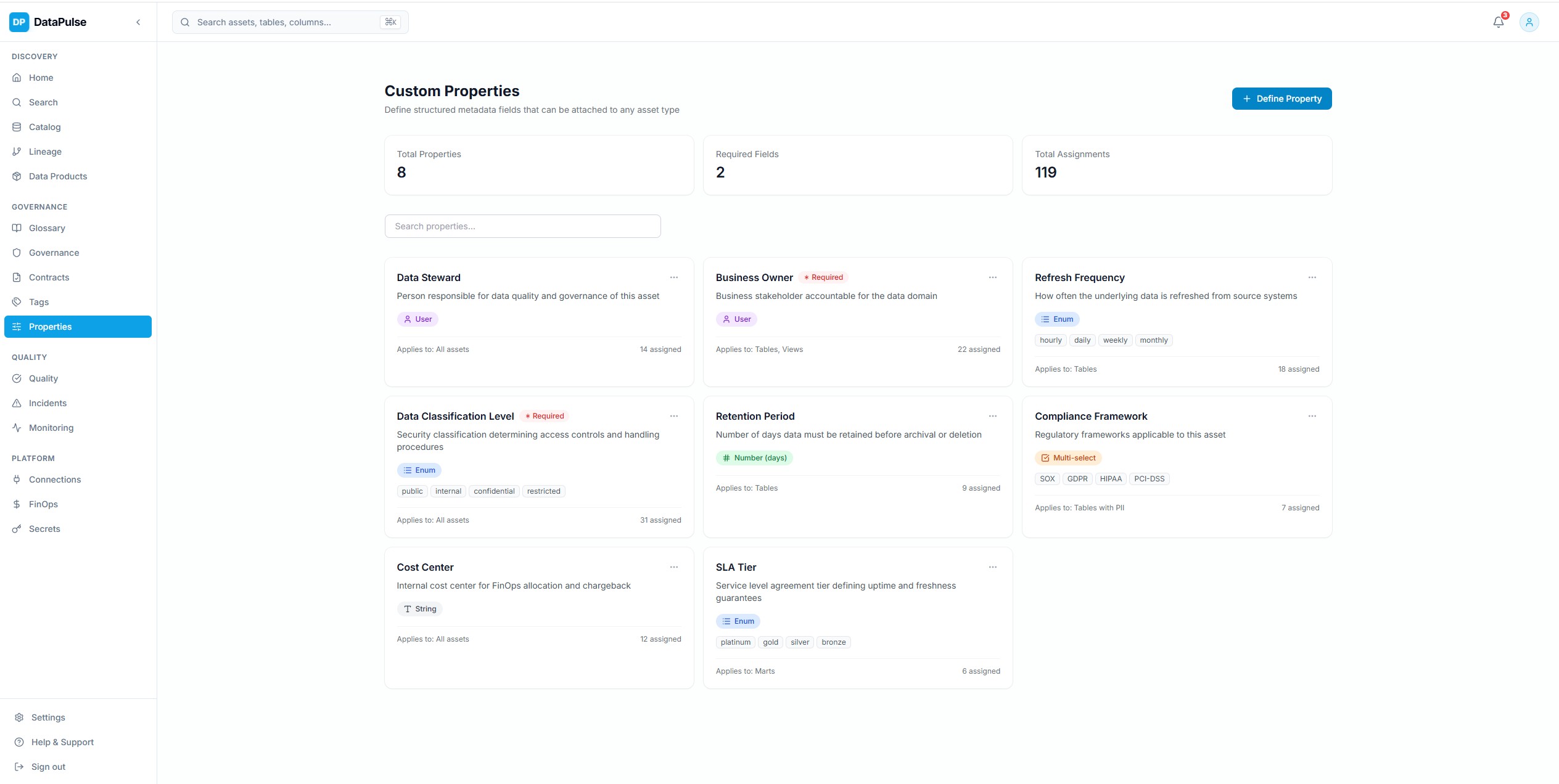
Asset Properties & Metadata
Rich metadata view per asset with schema details, column types, tags, descriptions, ownership, lineage context, and change history. Custom properties support domain-specific metadata enrichment.
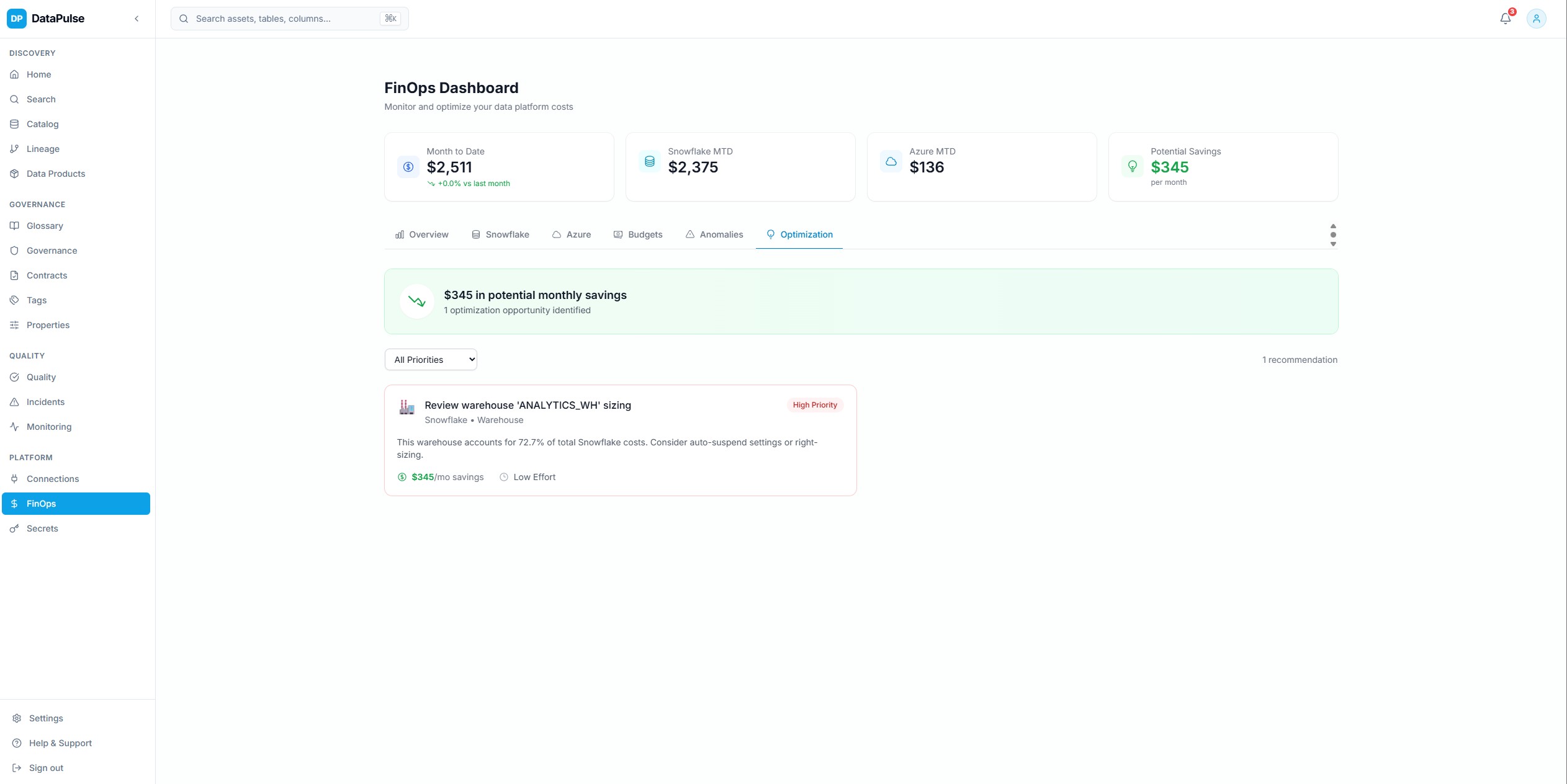
FinOps Cost Optimization
Cost optimization recommendations based on usage patterns — identify underutilized Snowflake warehouses, over-provisioned resources, and cost anomalies with actionable remediation guidance.
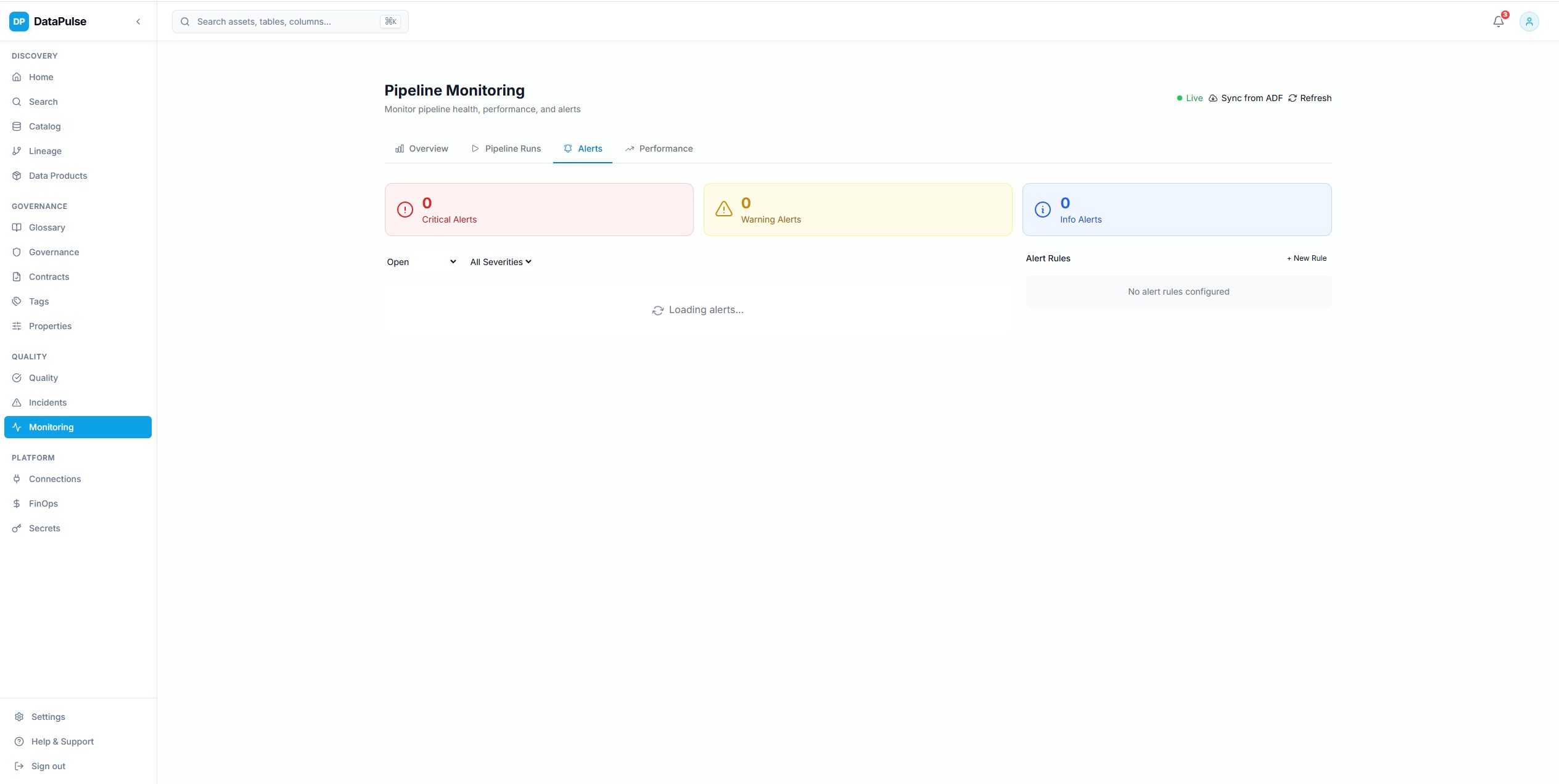
Pipeline Alert Configuration
Configurable alert rules on pipeline failures, timeouts, SLA breaches, and anomalies. Notifications routed to Slack and Microsoft Teams with full incident context and suggested remediation.
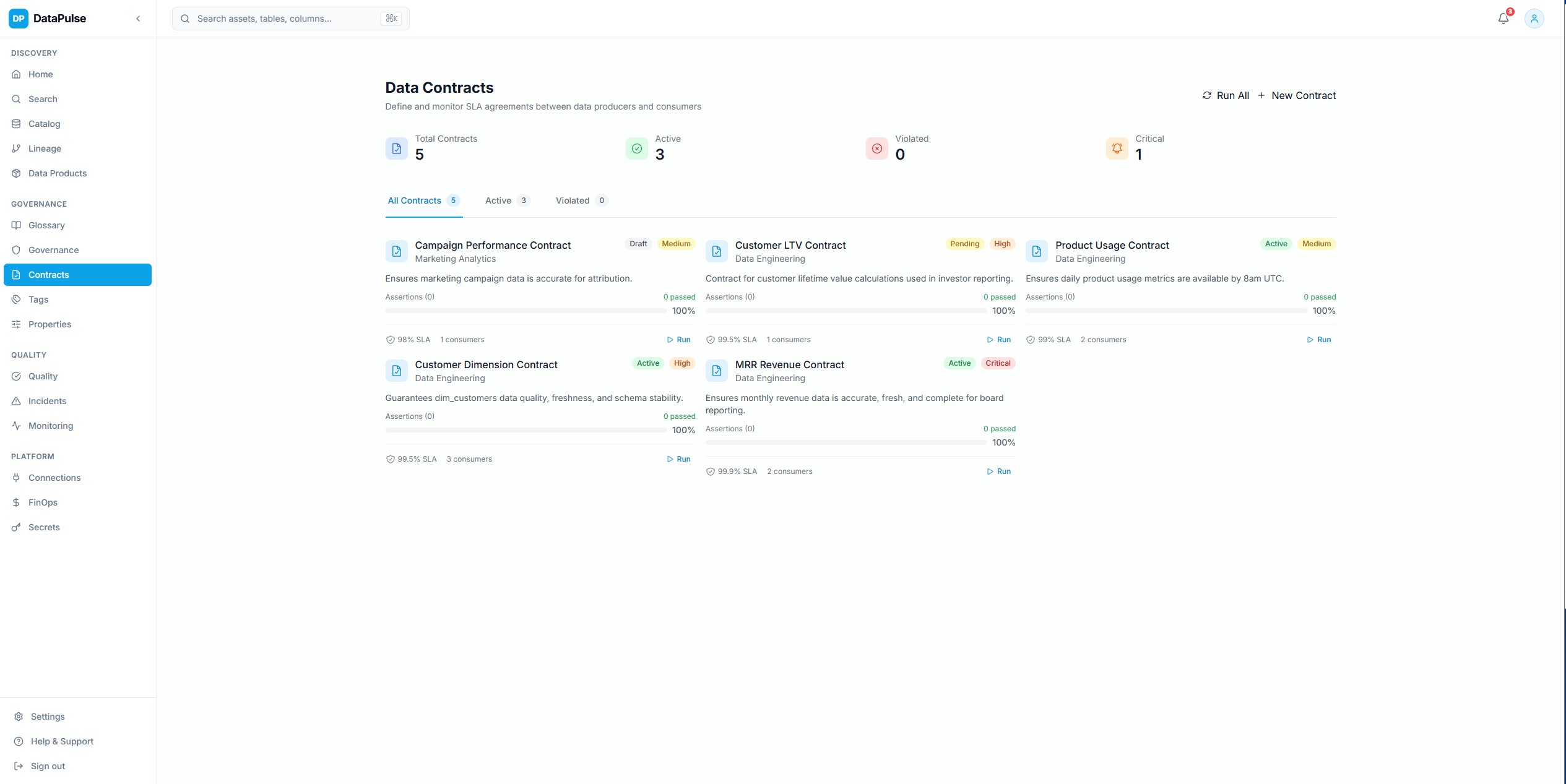
Data Contracts
Define and enforce data contracts with SLAs on freshness, completeness, schema stability, and quality thresholds. Contracts bridge data producers and consumers with clear expectations.
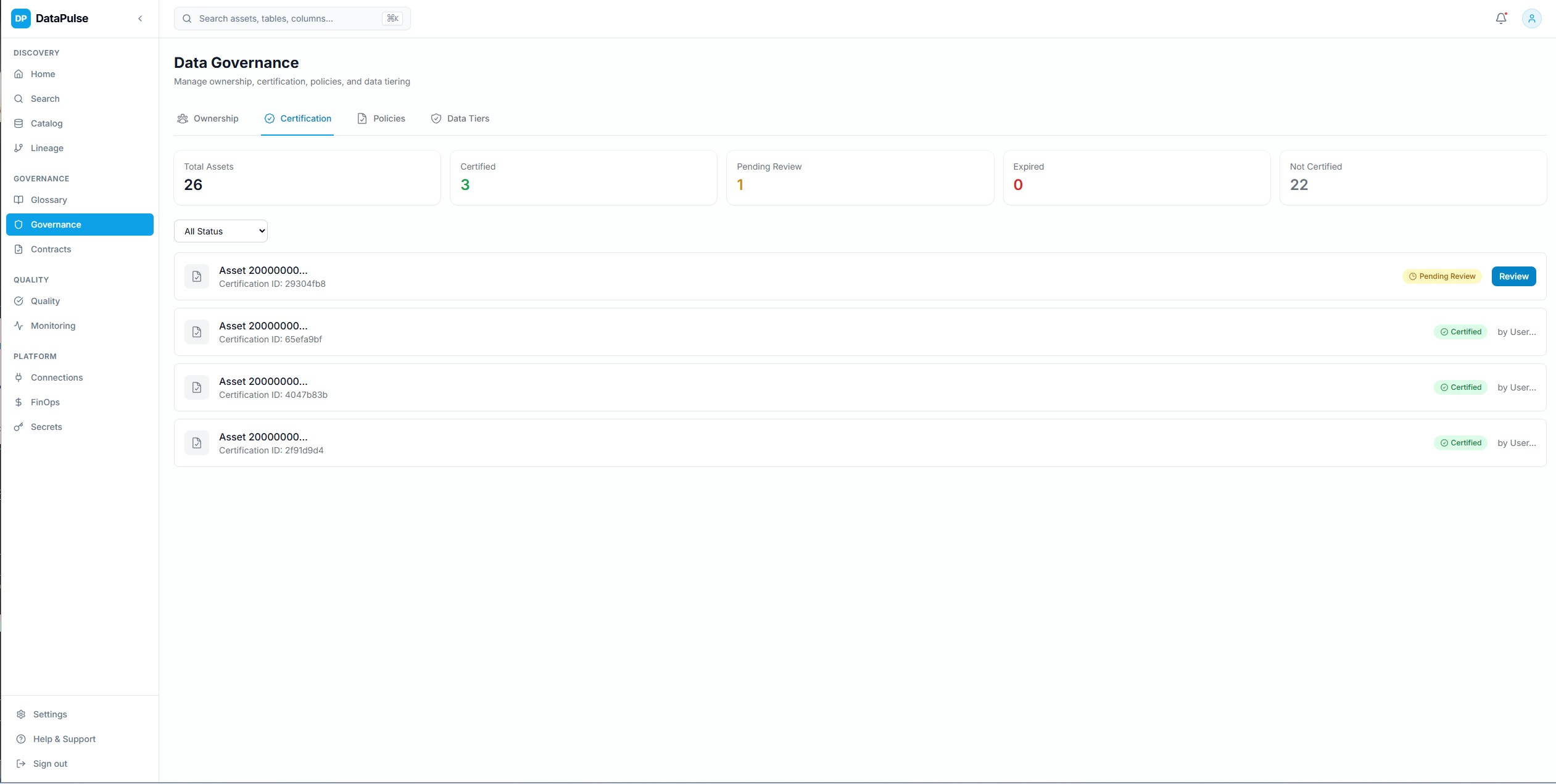
Governance Certification
Certification workflows for data assets — request, review, approve, and track certifications with audit trails. Certified assets surface prominently in search and catalog views.
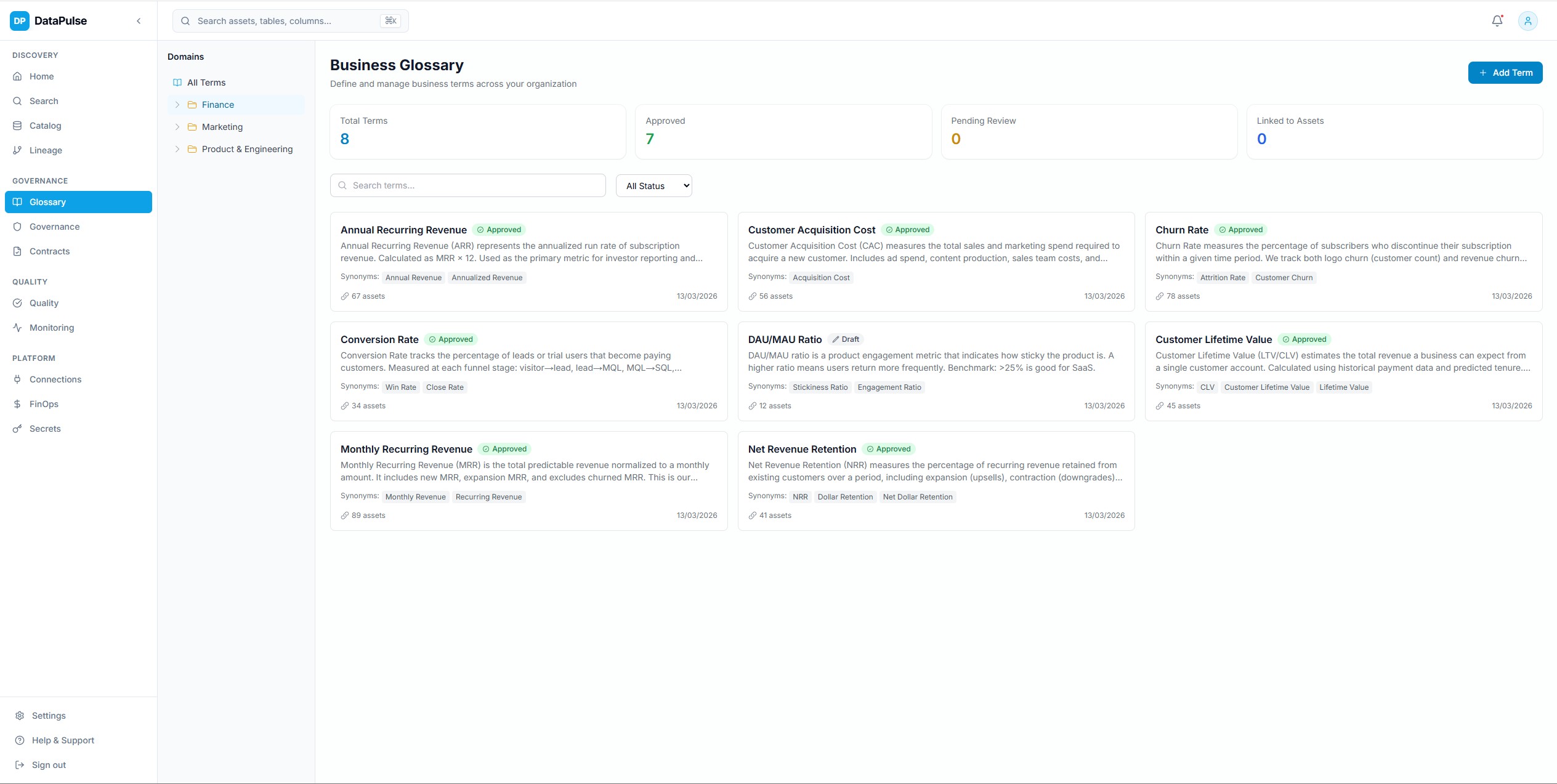
Business Glossary
Centralized business glossary with term definitions, domain ownership, and asset linking. Bridges the gap between business language and technical metadata.
Tech Stack
Built with
Framework
Data
AI
UI
Infra
Languages
Python 3.11TypeScriptSQLGraphQLYAMLCypherDockerfileWhat this project proves