
Comply-Agent
An AI compliance platform that turns regulatory analysis into a traceable operating system instead of a document-heavy consulting exercise.
Assessment cycle
Weeks -> hours
The product compresses manual control review into a guided digital workflow.
Framework coverage
2 core regulations
NIS2 and DORA are mapped into structured controls and evidence-backed analysis.
Operational depth
16 background tasks
Document processing, AI analysis, reporting, and monitoring work is distributed asynchronously.
Observability layers
3 stacked views
Sentry, Prometheus/Grafana, and Langfuse trace the product from infra to token-level AI behavior.
The Problem
What this project had to solve
Regulatory compliance work is usually scattered across spreadsheets, policy files, manual interviews, and generic consulting decks. Comply-Agent reframed that process as a product workflow with evidence, scoring, and remediation all in one place.
Comply-Agent was designed for organizations facing NIS2 and DORA pressure without the time or internal structure to run heavyweight audits manually. The product combines document ingestion, retrieval, AI analysis, and progress tracking into a workflow that makes compliance visible, structured, and actionable.
The backend uses FastAPI with an async-first service architecture, PostgreSQL for structured data, Qdrant for vector search, Redis and Celery for background execution, and a guarded LLM layer built with PydanticAI. The frontend translates that complexity into a dashboard-led experience with guided onboarding, per-control analysis, and an assistant that stays grounded in uploaded evidence.
What makes the project credible is not only the AI layer. It is the operational posture around it: prompt-injection defenses, audit trails, observability through Langfuse and OpenTelemetry, and infrastructure monitoring across the full stack. The goal was to build something teams could trust, not just demo.
What changed
Instead of treating compliance as a consulting output that gets stale the moment it is delivered, the product turns it into a living system: upload evidence, classify exposure, analyze controls, review gaps, and track remediation from a single command surface.
Why it was hard
The difficult part was not producing answers. It was engineering confidence around those answers: retrieval quality, human override paths, circuit breakers, queue discipline, and enough telemetry to explain why the system responded the way it did under real load.
Constraints
- The system had to stay IP-safe while still demonstrating technical depth publicly.
- AI answers needed to be grounded, reviewable, and auditable instead of sounding persuasive but unverifiable.
- Heavy document processing and control analysis had to happen without blocking the product experience.
My role
- Defined the product architecture from the data model to the deployment topology.
- Structured the ingestion, retrieval, and analysis pipeline across FastAPI, Celery, PostgreSQL, Qdrant, and Redis.
- Designed the dashboard, assistant, and review flows for analyst-grade usability.
- Built observability and safety patterns so the AI layer could be debugged and trusted in production.
Proof
What the product actually looks like
Real screens from the product — each one supports a specific argument about clarity, control, or observability.
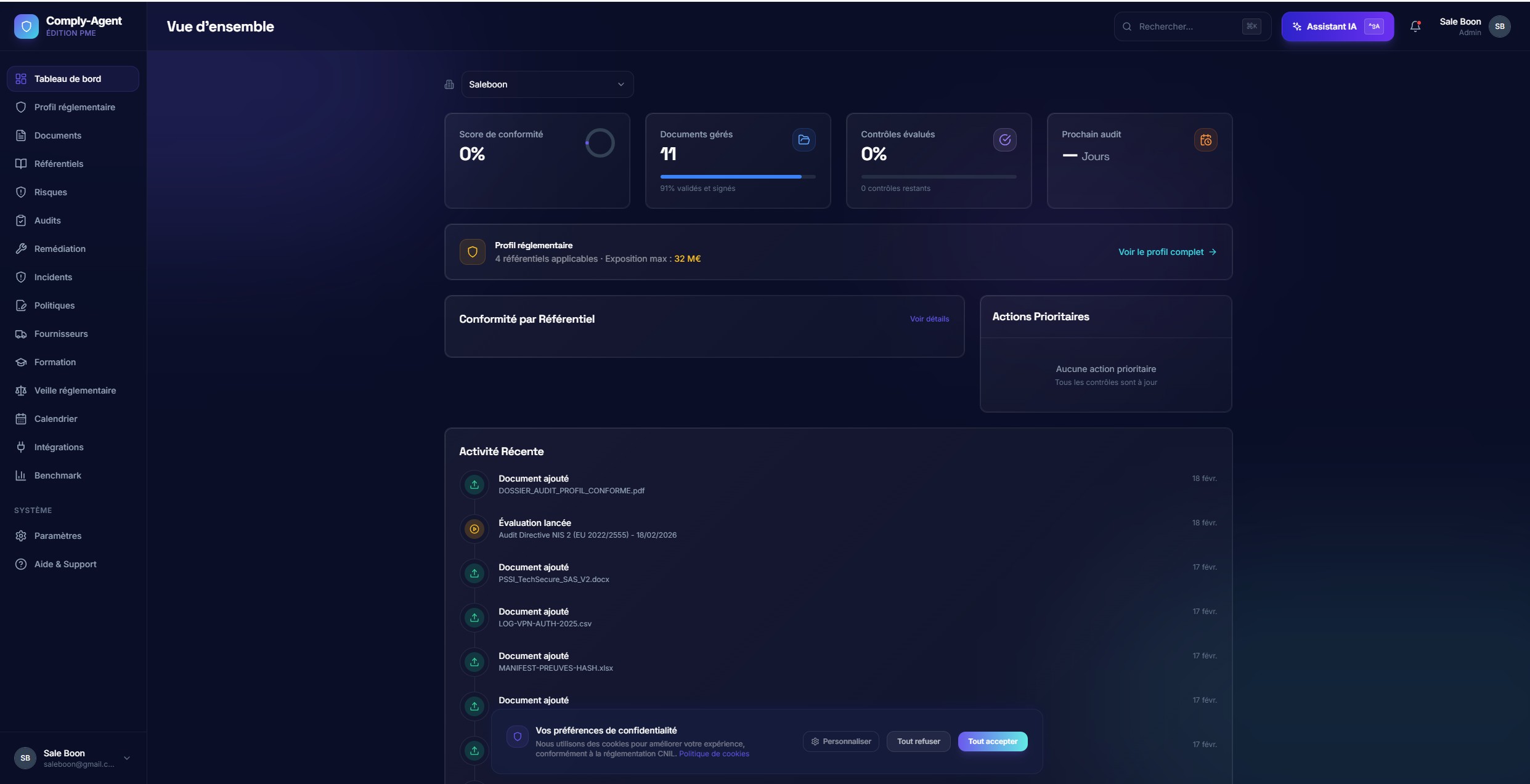 Command CenterClick to view full size
Command CenterClick to view full sizeCompliance Command Surface
A dashboard that answers the operational questions first: where do we stand, what changed, and what needs action next.
The product leads with decisions and remediation, not a wall of static framework content.
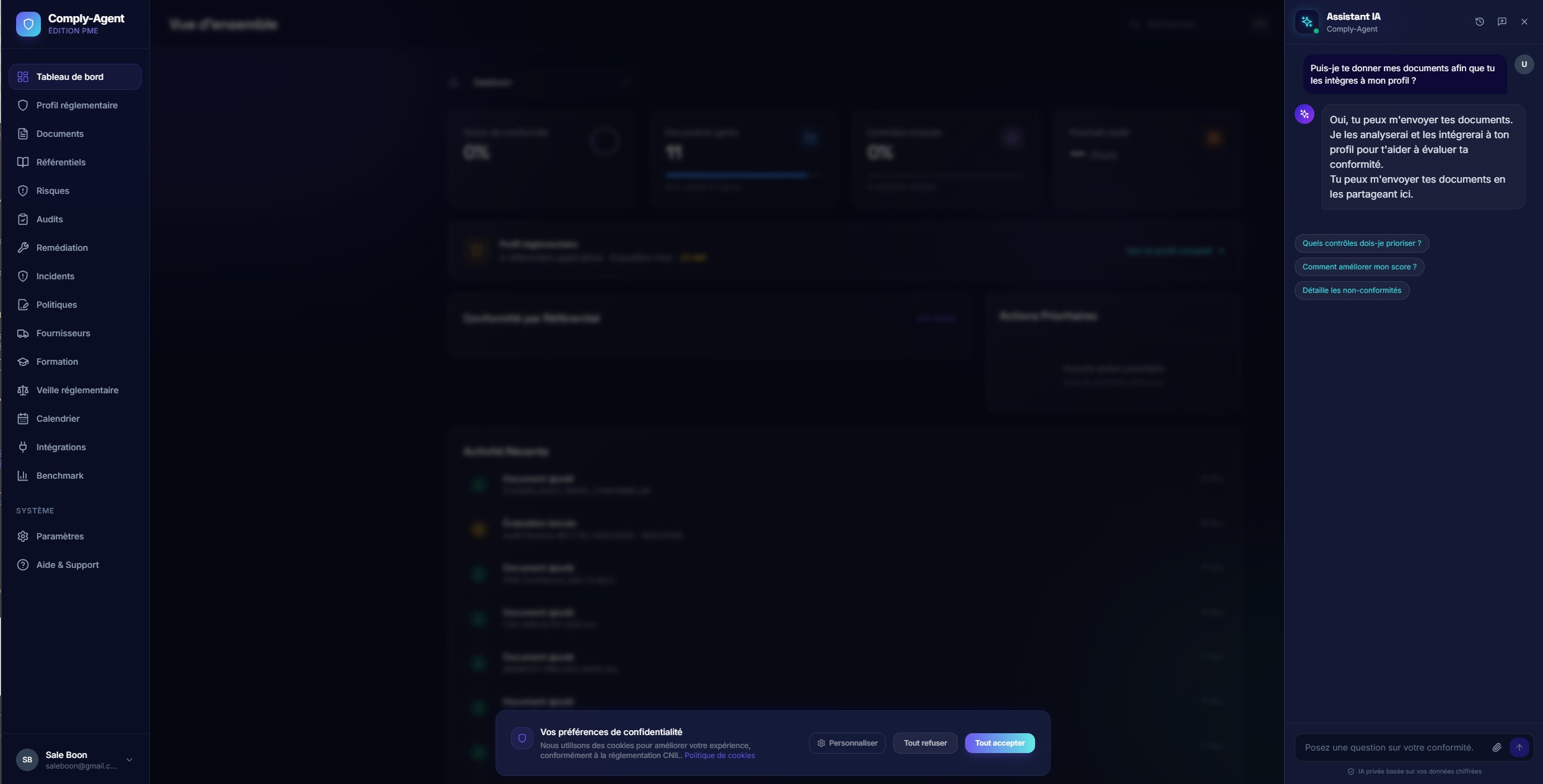 Evidence EngineClick to view full size
Evidence EngineClick to view full sizeGrounded AI Assistant
The assistant streams answers from company documents and suggests follow-ups instead of behaving like an unbounded chatbot.
Retrieval quality and response framing were designed to support trust, not novelty.
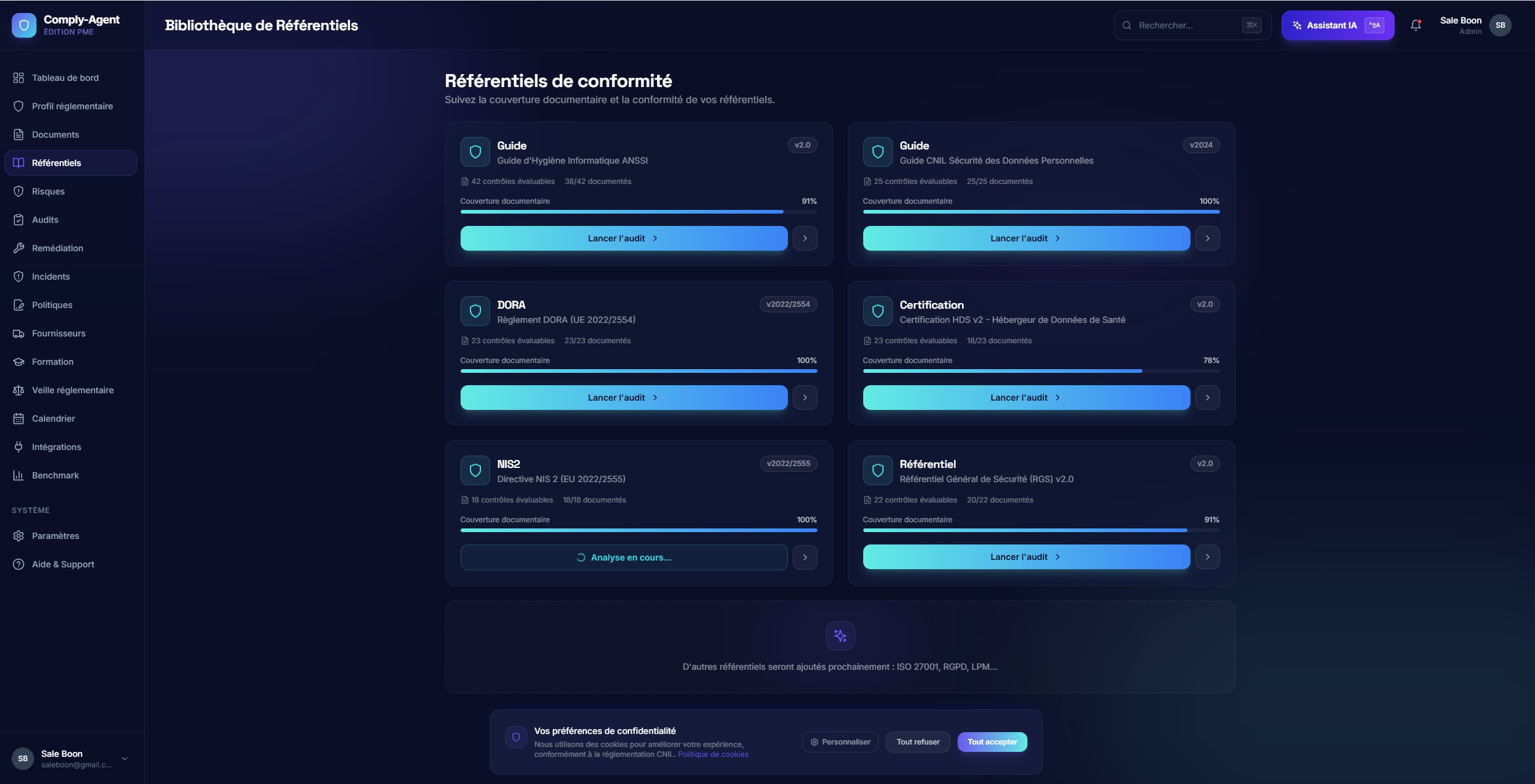 Analyst WorkflowClick to view full size
Analyst WorkflowClick to view full sizeControl-by-Control Review
Per-control assessments expose evidence, status, and override paths so the human reviewer stays in control.
This is where AI output becomes operationally useful: structured, reviewable, and actionable.
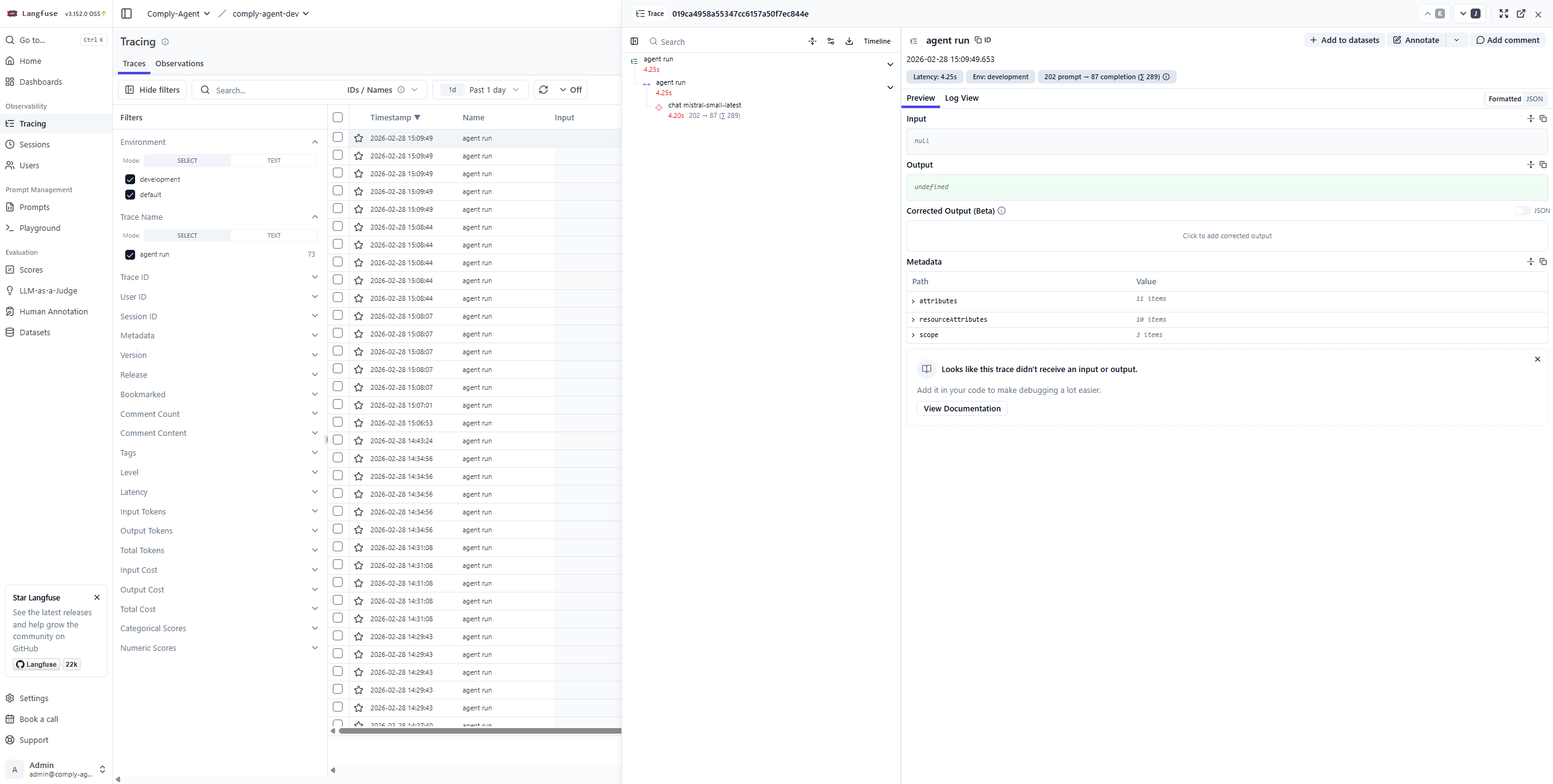 Proof LayerClick to view full size
Proof LayerClick to view full sizeLLM Trace Visibility
Every generation is observable through trace, latency, token usage, and routing information.
The observability layer makes iteration faster and turns model behavior into something debuggable.
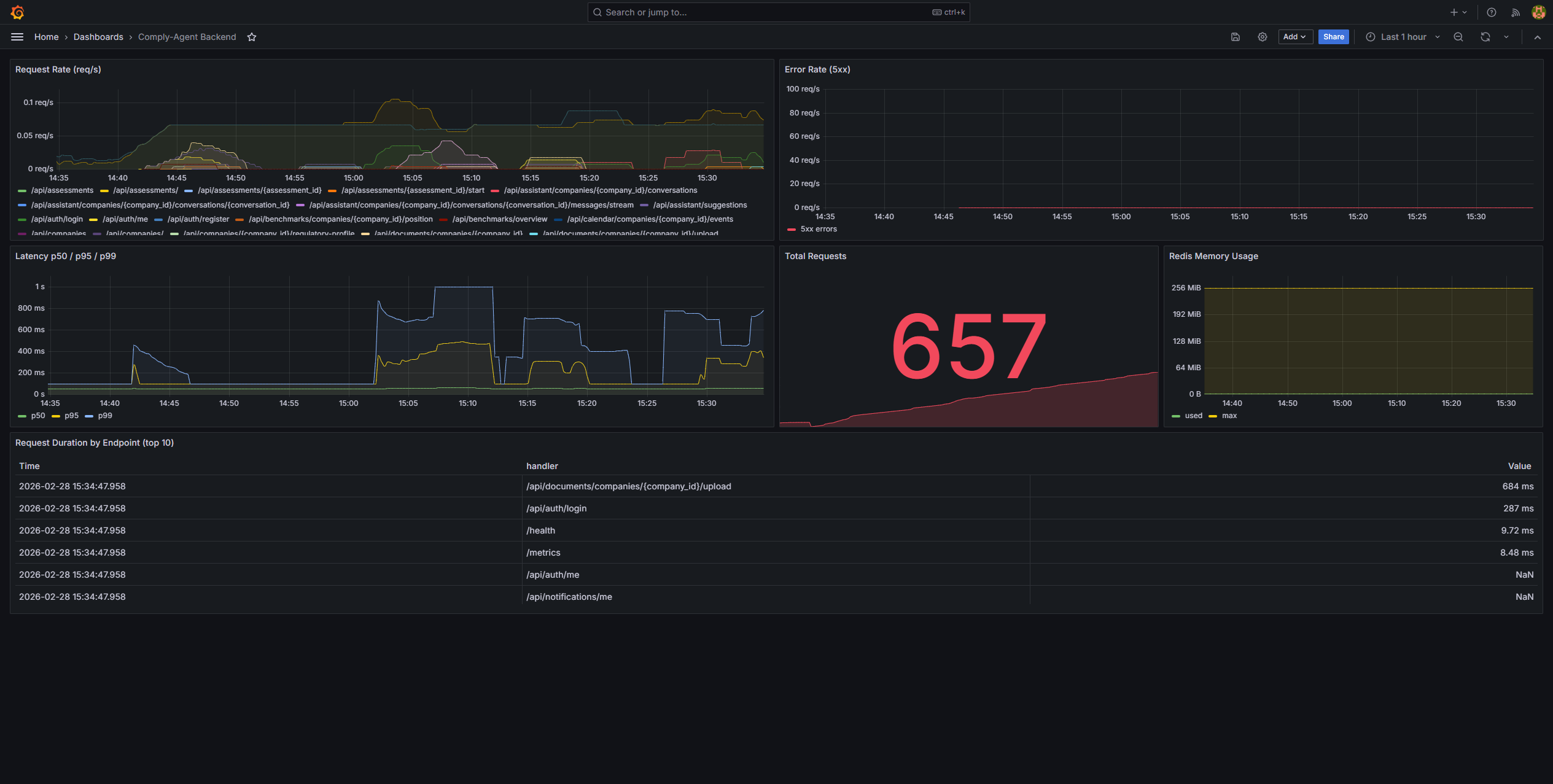 Ops SignalClick to view full size
Ops SignalClick to view full sizeInfrastructure Health
API, worker, database, and cache health are visible alongside the product experience.
AI features were treated as production systems from day one, not as demo-only embellishments.
Decisions
Tradeoffs that shaped the product
The strongest work is visible in the choices made under pressure, not just in the final interface.
Hybrid retrieval over naive similarity search
Challenge
Compliance documents are long, noisy, multilingual, and full of near-duplicate evidence.
Decision
The retrieval layer combines multi-query expansion, HyDE, and reranking before analysis.
Tradeoff
This adds orchestration and latency, but it sharply improves evidence relevance and answer quality.
Asynchronous task mesh over request-bound processing
Challenge
Parsing, chunking, embedding, and report generation are too expensive to tie directly to user requests.
Decision
Document and analysis work moved into Celery-driven background pipelines with Redis coordination.
Tradeoff
Operational complexity increases, but the user experience stays responsive and the system scales more cleanly.
Observability before scale
Challenge
LLM systems become expensive and opaque very quickly when instrumentation arrives too late.
Decision
Tracing, metrics, and error monitoring were treated as core product features, not deployment extras.
Tradeoff
The setup cost is higher early on, but debugging and trust improve dramatically once usage grows.
Architecture
How data flows through the system
Ingest
Users upload policy files, audit evidence, and operational documents into a structured intake flow.
→ The product starts from real company evidence rather than generic questionnaires.
Parse + chunk
Docling and background jobs normalize files, extract structure, and prepare semantically useful chunks.
→ Messy source material becomes retrieval-ready without blocking the interface.
Index + retrieve
Embeddings are stored in Qdrant and combined with metadata filtering and reranking during retrieval.
→ Relevant evidence can be pulled quickly and defended during review.
Analyze controls
PydanticAI orchestrates control-level reasoning with safety checks, routing, and audit-aware output formatting.
→ Assessments become structured, explainable product outputs instead of opaque model text.
Operate + monitor
Dashboards, assistant flows, and observability surfaces expose product state, AI behavior, and infra health.
→ Teams can act on the system and trust what it is doing under production conditions.
Comply-Agent uses a layered monolith on the backend: FastAPI routes delegate to services, services coordinate repositories across PostgreSQL, Qdrant, and Redis, and Celery handles heavy asynchronous work. The frontend is a dashboard-led Next.js application that exposes the system as a guided operating surface rather than a generic AI chat experience.
Product surfaces
The interfaces that carry the experience
Compliance Dashboard
A command surface for framework progress, non-compliant controls, and the actions that matter next.
AI Compliance Assistant
A grounded assistant that answers from uploaded evidence and streams responses in a review-friendly format.
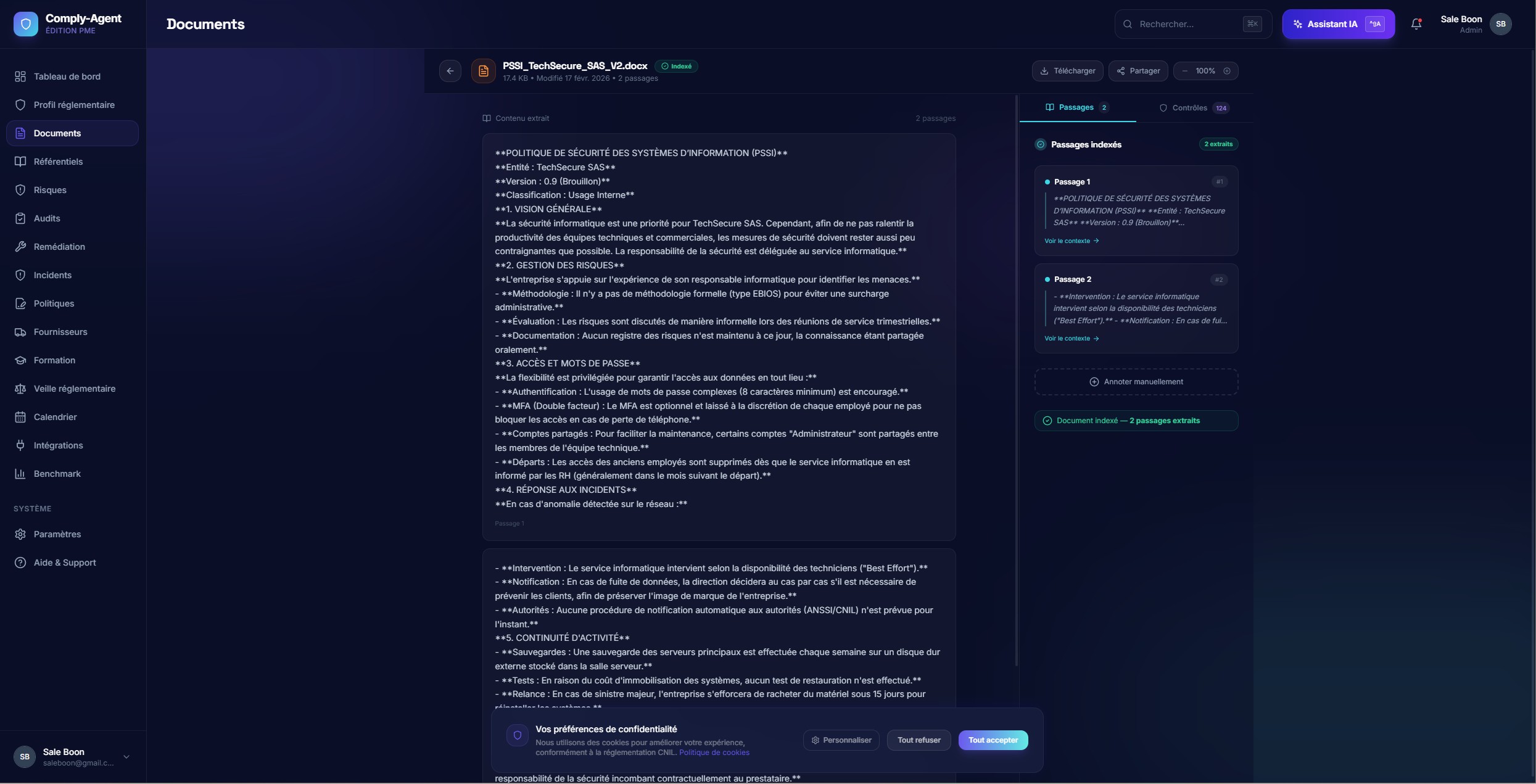
Document Intelligence Pipeline
An end-to-end ingestion and indexing flow that turns dense source files into retrieval-ready knowledge.
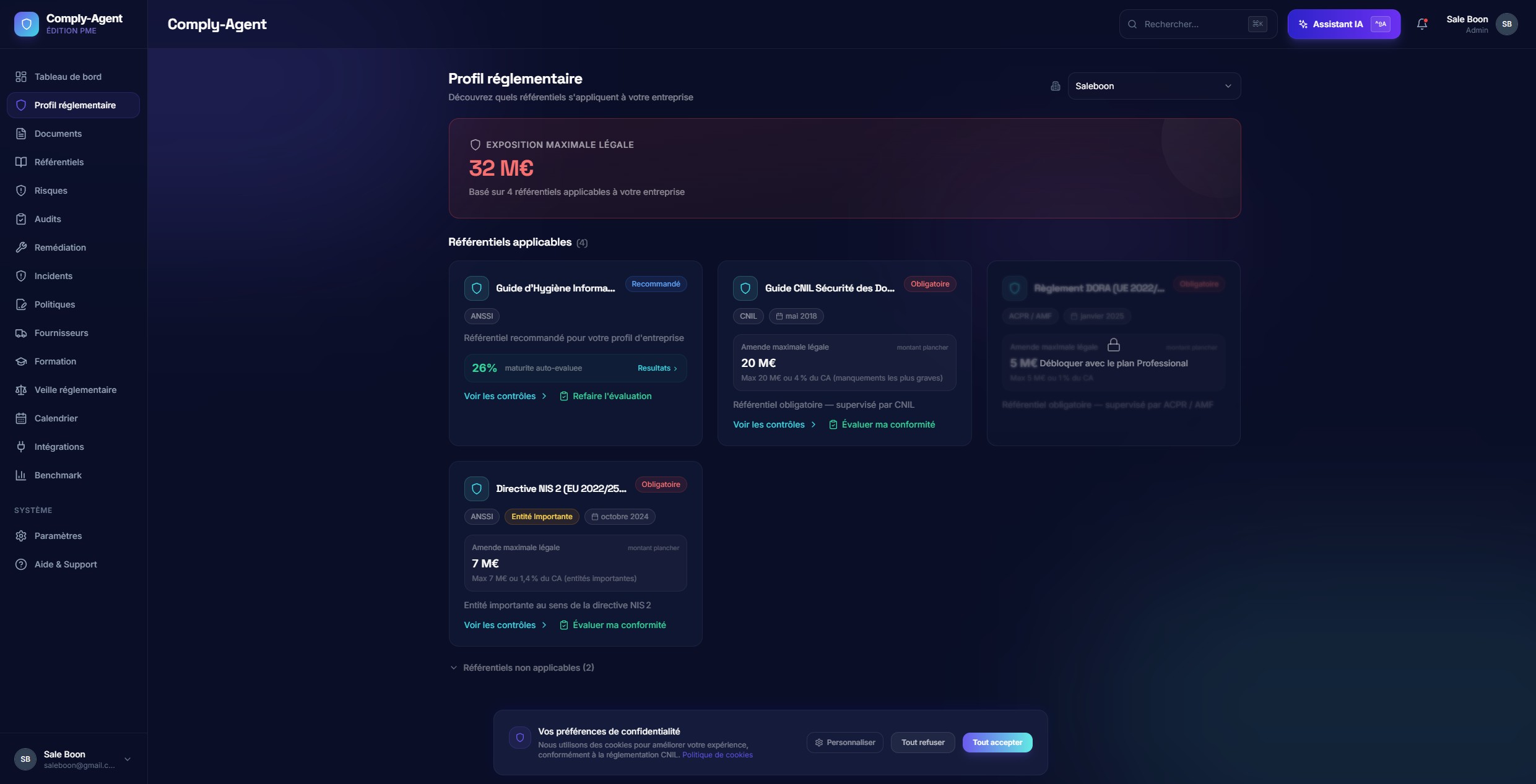
Regulatory Profile
A classification layer that identifies regulatory exposure, applicable frameworks, and risk context.
Framework & Control Analysis
The analyst surface where evidence-backed scoring, gap detection, and override workflows come together.
LLM Observability
Trace-level visibility for model usage, cost, latency, and routing decisions across the assistant layer.
Infrastructure Monitoring
Production dashboards cover API performance, workers, database health, and cache behavior.
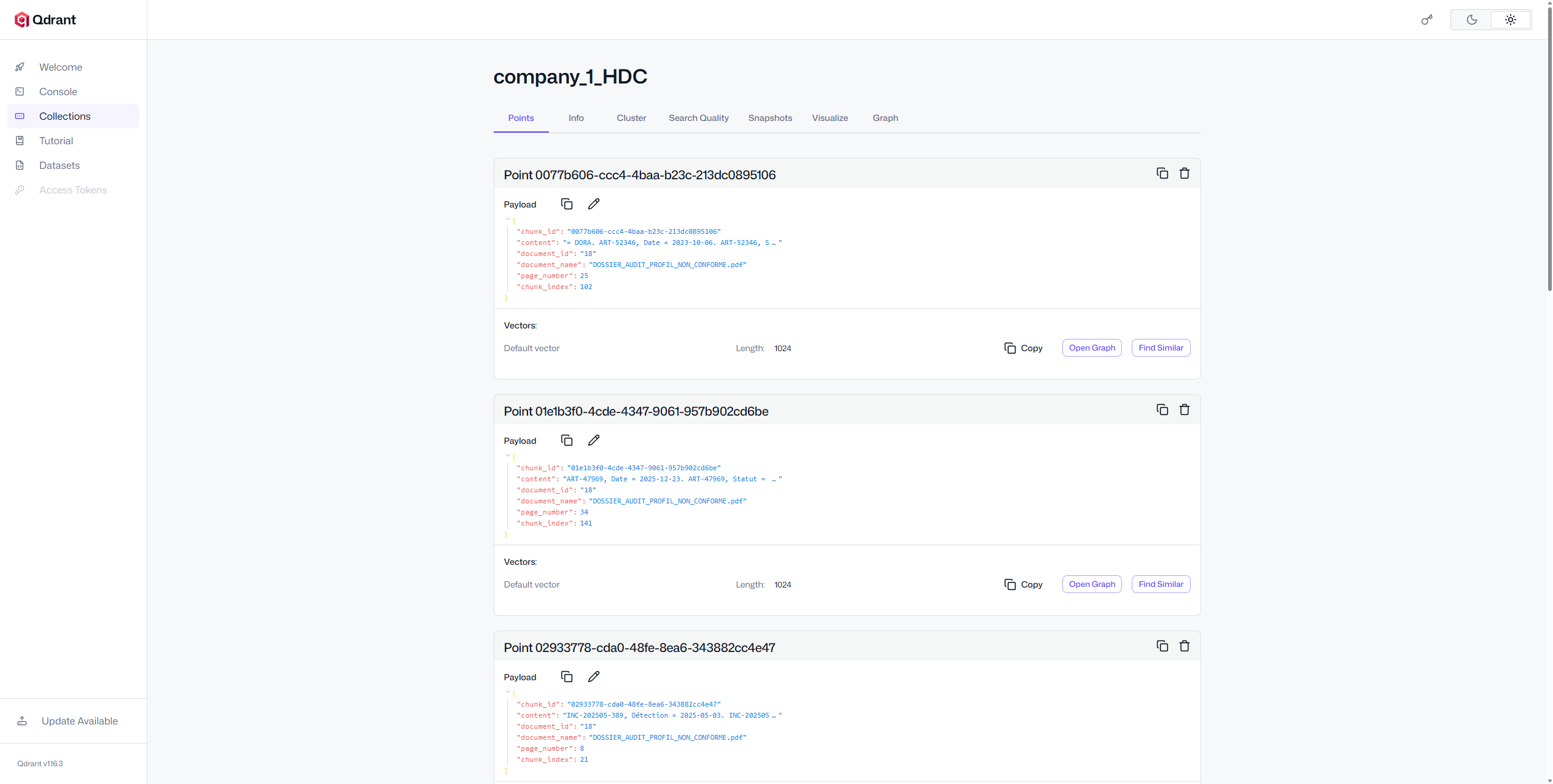
Vector Search Engine
A semantic retrieval layer that powers grounded responses and control-level evidence gathering.
Tech Stack
Built with
FastAPI
Backend API framework
PostgreSQL
Primary relational database
Redis
Cache, broker, and rate limiting
Celery
Distributed task queue
Qdrant
Vector database for RAG
Mistral AI
LLM inference provider
Langfuse
LLM observability
Grafana
Infrastructure dashboards
Prometheus
Metrics collection
Framework
UI
Data
AI
Infra
Languages
TypeScriptPythonSQLCSS/TailwindWhat this project proves